
Getting a feel for the pulse of Cloud Computing can be a difficult endeavor. According to recent Google search trends "Cloud Computing" is at an all time high in terms of raw search queries. This has also been confirmed by analysts reports such as Gartner's Hype Cycle which shows Cloud computing at what they aptly describe as the peak of inflated expectations. For me tools like Google Trends & Google Insights helps shed light on Cloud Computing from a search engine point a view. But sadly does little in translating into actual financial facts and figures - the stuff that actually matters.
Trying to look beyond the hype and see if people are actually making money or getting work done should be the real litmus test in terms of gauging the business opportunity for cloud computing -- and at the end of the day it's probably a better statistic. But then again these sorts of "real world" revenue & sales pipeline stats are not nearly as easy to get. So I thought I'd take a moment, and discuss some of the recent success we've seen in our segment of the cloud world.
Generally, the Fall tends to be the hot sales season in IT where IT folks are coming back from summer vacations with budgets that must be spent before the end of the year. So this time of year does act as a kind of predictor of future sales opportunities. To put it simply, in IT if you can't sell your product or service in the Fall, you're probably not going to sell at all. This is as true in Cloud Computing as it is in any other area of information technology.
When speaking to the opportunity for cloud computing, I can only speak from my vantage point as a Cloud Service Provider enablement platform vendor. At Enomaly we specifically target service providers and hosting firms who are looking to roll out public "EC2" like infrastructure as a service. From our point of view it has become increasingly clear that any hosting firms that don't have cloud service strategies or offerings in place are quickly beginning to see huge revenue erosion. This has caused a significant influx of interest from a wide variety of hosting related companies that run the gamut from smaller VPS style resellers to multi-national telecommunication companies and everything in between.
An analysis by Guy Rosen also sheds some light on the cloud opportunity in which he estimates that Amazon Web Services (AWS) is provisioning 50,000 EC2 server instances per day. A 50K/day run rate would imply a yearly total of over 18 million provisioned instances. Based on these numbers, one could surmise, that a significant portion of these 50k in EC2 instances are directly coming out of the pockets of traditional hosting and data centers. In the hosting space, this kind of cloud leakage has become a major issue. One need not do more then monitor traffic to amazon or other cloud providers to get an idea of potential revenue walking out the door.
As a fast growing self funded company we don't have the luxury of spending large amounts on our marketing and sales efforts. For the most part we rely on word mouth and organic search engine optimization for our inbound sales channel. Because we spend a grand total of $0.00 dollars on our marketing efforts, our organic website traffic / inbound sales inquires also acts as a kind of simple market research tool. Based on the this very unscientific research tool, interest in cloud platforms is booming.
Over the last few months something interesting has happened. We've seen interest in our cloud service provider platform grow from dozens of inquires a month to dozens per day. Again, I can't say if this is a broader trend or limited to our sector, but from our vantage it has never been a better time to be in cloud computing. I'm just curious if others are seeing similar levels of interest for their cloud related products and services. I for one certainly hope so, because the better we do collectively, the better we do individually.
Wednesday, September 30, 2009
Thursday, September 24, 2009
Swedish Government Bans the Word "Bank" from .SE Domains
A major uproar has been brewing in Sweden over a recent government ruling banning the word "bank" from any Swedish domains that do not fit the official definition of a financial banking institution. (Basically *bank.se) On Thursday The Pirate Bay pledged it's support joining in the protest against the Swedish Post- and Telecoms Authority (PTS) The list has since started growing by hundreds of names per hour. It is run by the web host Binero to protest against the PTS decision to subject all Swedish se-domain names containing the word “bank” to an inspection prior to registration. This to insures that anyone that might be confused with a bank actually fulfills the legal requirements for one. It is a departure from international standards, where issues are solved, usually by a Uniform Dispute Resolution Process (UDRP) once they arise after registration.
The big concern isn't specifically about the word bank so much as it sets a precedent for other words in the future. Think about if words such as cloud or science or music require official approval by a government agency before you could register the domain.
The Swedish Bankers’ Association have lobbied for restrictions on domain names for a long time, making an interpretation of the Swedish law mandating that anyone using “Bank” as a name in their business must fulfill the requirements of one.
Their arguments is that the banks have not been able to show evidence of fraudulent “bank”-sites, that typosquatting would not be stopped, whereas many Swedes would have a more difficult time registering, that scrutinizing new businesses before domain registration would be injust and, above all, that the approval of name scrutinization prior to registration would spread to many other names; titles protected by law, names of public authorities, brands, racist words etc.
“To diverge from the democratic country norm of problem resolution post rather than pre registration, and to do it for a common word and name like “Bank” is dangerous. It makes it legally and logically plausible for many groups to lobby for scrutinizing an unforeseeable number of other words and names pre registration as well,”said Binero CEO Anders Aleborg, continuing:
“All countries have the same problem and lobby groups like our big banks. There is a big risk that this form of net censorship might spread if Sweden does it.”
--------------------
![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-id=2e813a8b-ef9d-4d1d-8810-fb86d03e3e1e)
The big concern isn't specifically about the word bank so much as it sets a precedent for other words in the future. Think about if words such as cloud or science or music require official approval by a government agency before you could register the domain.
The Swedish Bankers’ Association have lobbied for restrictions on domain names for a long time, making an interpretation of the Swedish law mandating that anyone using “Bank” as a name in their business must fulfill the requirements of one.
Their arguments is that the banks have not been able to show evidence of fraudulent “bank”-sites, that typosquatting would not be stopped, whereas many Swedes would have a more difficult time registering, that scrutinizing new businesses before domain registration would be injust and, above all, that the approval of name scrutinization prior to registration would spread to many other names; titles protected by law, names of public authorities, brands, racist words etc.
“To diverge from the democratic country norm of problem resolution post rather than pre registration, and to do it for a common word and name like “Bank” is dangerous. It makes it legally and logically plausible for many groups to lobby for scrutinizing an unforeseeable number of other words and names pre registration as well,”said Binero CEO Anders Aleborg, continuing:
“All countries have the same problem and lobby groups like our big banks. There is a big risk that this form of net censorship might spread if Sweden does it.”
--------------------
For more information:
Anders Aleborg, CEO, Binero, +46 768-04 42 00, [email protected]
Erik Arnberg, Marketing Manager, Binero, +46 70-398 75 34, [email protected]
Swedish Government IT-advisor Patrik Fältström (Paf) blog: http://stupid.domain.name/node/812#comment
.SE home page re: this: http://www.iis.se/en/domaner/bank-i-domannamn/
PTS English home page: http://www.pts.se/en-gb/
Namnbank.se (Swedish): http://www.namnbank.se
Press pictures, Anders Aleborg, http://blogg.binero.se/press/
Binero AB is a web host and registrar with the ambition of being the friendliest in Sweden; transparency, honesty and friendliness.Tuesday, September 22, 2009
New Simple Cloud Storage API Launched
PHP/Zend, Microsoft, IBM, Rackspace, GoGrid and Nirvanix have launched a new low level cloud API for PHP called the "Simple Cloud API". The API can best be described as low level storage focused API (An API for other API's). In a sense it's a way to create other higher level programmatic API interfaces such as REST or SOAP using an easy, yet portable PHP programming environment. It allows you to easily interact with a variety of cloud interfaces including support for File Storage, Document Storage, and Simple Queue services. The API is not a web service; it is an API that exposes common operations in application services offered by different vendors, making it easier for PHP developers to build ‘cloud native’ applications.
According to the website, "The Simple Cloud API is here to bring cloud technologies to PHP and the PHP philosophy to the cloud. With it, developers can start writing scalable and highly available applications that are still portable. If you're looking for code to start playing around with immediately, you'll find the first file storage, document storage, and simple queue interfaces."
Interestingly the goal of API is not be a standard, but instead to foster an open source community that makes it easier for developers to use cloud application services by abstracting insignificant API differences. Another goal of this initiative is to define interfaces to be implemented as a new Zend Framework component called ‘Zend_Cloud’. The Zend Framework will provide a repository of php appplication to host code for the Zend_Cloud.
Check out the project at http://www.simplecloud.org
According to the website, "The Simple Cloud API is here to bring cloud technologies to PHP and the PHP philosophy to the cloud. With it, developers can start writing scalable and highly available applications that are still portable. If you're looking for code to start playing around with immediately, you'll find the first file storage, document storage, and simple queue interfaces."
Interestingly the goal of API is not be a standard, but instead to foster an open source community that makes it easier for developers to use cloud application services by abstracting insignificant API differences. Another goal of this initiative is to define interfaces to be implemented as a new Zend Framework component called ‘Zend_Cloud’. The Zend Framework will provide a repository of php appplication to host code for the Zend_Cloud.
Check out the project at http://www.simplecloud.org
Monday, September 21, 2009
Public Cloud Infrastructure Capacity Planning
In the run of a day I get a lot of calls from hosting companies and data centers looking to roll out public cloud infrastructures using Enomaly ECP. In these discussions there are a few questions that everyone seems to ask.
- How much is it going to cost?
- What is the minimum resources / capacity required to roll out a public cloud service?
Both questions are very much related. But to get to and idea of how much your cloud infrastructure is going to cost, you first need to fully understand what your resource requirements are and how much capacity (minimum resources) will be required to maintain an acceptable level of service and hopefully turn a profit.
In traditional dedicated or shared hosting environment, capacity planning is typically a fairly straight forward endeavor, (a high allotment of bandwidth and a fairly static allotment of resources), a single server (or slice of a server) with a static amount of storage and ram. If you run out of storage, or get too many visitors, well too bad. It is what it is. Some managed hosting providers offer more complex server deployment options but generally rather then one server you're given a static stack of several, but the concept of elasticity is not usually part of the equation.
Wikipedia gives a pretty good overview of concept of capacity planning which is described as process of determining the production capacity needed by an organization to meet changing demands for its products. Although this definition is being applied to a traditional business context, I think it works very well when looking at public cloud infrastructure.
Compounding cloud capacity planning is the idea of elasticity. Now not only are you planning for typical usage, you must also try to forecast for sudden increases in demand across many customers using a shared multi-tenant infrastructure. In ECP we use the notion of capacity quota's where new customers are given a maximum amount of server capacity, say 20 VM's or 1TB of storage. For customers who require more, they then make a request to the cloud provider. The problem with this approach is it gives customers a limited amount of elasticity. You can stretch, but only so far. Another strategy we sometimes suggest is a flexible quota system (Match strategy) where after a period of time, you now trust the customer and automatically give them additional capacity or monitor their usage patterns and offer it to them before it becomes a problem. This is similar to how you seem to magically get more credit on your credit cards for being a good customer or get a call when you buy an unexpected big ticket item.
The use of a quota system is an extremely important aspect in any capacity / resource planning you will be doing when either launching or running your cloud service. A quota system gives you a predetermined level of deviation across a real or hypothetical pool of customers. Which with out it, is practically impossible to adequately run a public cloud service.
Next you must think of the notion of overselling your infrastructure. Let's say your default customer quota is 20 virtual servers, what percentage of those customers are going to use 100% of their allotment? 50%, 30%, 10%? Again this differs tremendously depending on the nature of your customers deployments and your comfort level. At the end of the day to stay competitive you're going to need to oversell your capacity. Overselling provides you the capital to continue to grow your infrastructure, hopeful slightly faster then your customers capacity requirements increase. The chances of 100% of your customers using 100% of their quota is probably going to be slim, the question you need to ask is what happens when 40% of your customers are using 60% of their quota? Does this mean 100% of the available capacity is being used? Cloud capacity planning also directly effects things like your SLA's and Q0S. Regardless of your platform, it's never good idea to use 100% of your available capacity nor should you. So determining the optimal capacity and having away to monitor it is going to be a crucial aspect in managing your cloud infrastructure.
I believe to fully answer the capacity question you must first determine your ideal customer. Determine where your sweet spot is, who you're going after (the low end, high end, commodity or niche markets). This will greatly help you determine your customer's capacity requirements. I'm also realistic, there is no one size fits all approach. For the most part, Cloud Computing is a best guess game, there are no best practices, architectural guidelines or practical references for you to base your deployment on. What it comes down to to is experience. The more of these we do the better we can plan. This is the value that companies such as Enomaly and the new crop of cloud computing consultants bring. What I find interesting is the more cloud computing as a service model is being adopted by hosting firms, the more these hosters are increasingly coming to us not only for our cloud infrastructure platform, but to help them navigate though a scary new world of cloud capacity planning.![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-id=7e7a5f29-3db0-4bb2-87ac-f845456c679c)
- How much is it going to cost?
- What is the minimum resources / capacity required to roll out a public cloud service?
Both questions are very much related. But to get to and idea of how much your cloud infrastructure is going to cost, you first need to fully understand what your resource requirements are and how much capacity (minimum resources) will be required to maintain an acceptable level of service and hopefully turn a profit.
In traditional dedicated or shared hosting environment, capacity planning is typically a fairly straight forward endeavor, (a high allotment of bandwidth and a fairly static allotment of resources), a single server (or slice of a server) with a static amount of storage and ram. If you run out of storage, or get too many visitors, well too bad. It is what it is. Some managed hosting providers offer more complex server deployment options but generally rather then one server you're given a static stack of several, but the concept of elasticity is not usually part of the equation.
Wikipedia gives a pretty good overview of concept of capacity planning which is described as process of determining the production capacity needed by an organization to meet changing demands for its products. Although this definition is being applied to a traditional business context, I think it works very well when looking at public cloud infrastructure.
Capacity is defined as the maximum amount of work that an organization is capable of completing in a given period of time with the following calculation, Capacity = (number of machines or workers) × (number of shifts) × (utilization) × (efficiency). A discrepancy between the capacity of an organization and the demands of its customers results in inefficiency, either in under-utilized resources or unfulfilled customers.
The broad classes of capacity planning are lead strategy, lag strategy, and match strategy.
- Lead strategy is adding capacity in anticipation of an increase in demand. Lead strategy is an aggressive strategy with the goal of luring customers away from the company's competitors. The possible disadvantage to this strategy is that it often results in excess inventory, which is costly and often wasteful.
- Lag strategy refers to adding capacity only after the organization is running at full capacity or beyond due to increase in demand (North Carolina State University, 2006). This is a more conservative strategy. It decreases the risk of waste, but it may result in the loss of possible customers.
- Match strategy is adding capacity in small amounts in response to changing demand in the market. This is a more moderate strategy.
Compounding cloud capacity planning is the idea of elasticity. Now not only are you planning for typical usage, you must also try to forecast for sudden increases in demand across many customers using a shared multi-tenant infrastructure. In ECP we use the notion of capacity quota's where new customers are given a maximum amount of server capacity, say 20 VM's or 1TB of storage. For customers who require more, they then make a request to the cloud provider. The problem with this approach is it gives customers a limited amount of elasticity. You can stretch, but only so far. Another strategy we sometimes suggest is a flexible quota system (Match strategy) where after a period of time, you now trust the customer and automatically give them additional capacity or monitor their usage patterns and offer it to them before it becomes a problem. This is similar to how you seem to magically get more credit on your credit cards for being a good customer or get a call when you buy an unexpected big ticket item.
The use of a quota system is an extremely important aspect in any capacity / resource planning you will be doing when either launching or running your cloud service. A quota system gives you a predetermined level of deviation across a real or hypothetical pool of customers. Which with out it, is practically impossible to adequately run a public cloud service.
Next you must think of the notion of overselling your infrastructure. Let's say your default customer quota is 20 virtual servers, what percentage of those customers are going to use 100% of their allotment? 50%, 30%, 10%? Again this differs tremendously depending on the nature of your customers deployments and your comfort level. At the end of the day to stay competitive you're going to need to oversell your capacity. Overselling provides you the capital to continue to grow your infrastructure, hopeful slightly faster then your customers capacity requirements increase. The chances of 100% of your customers using 100% of their quota is probably going to be slim, the question you need to ask is what happens when 40% of your customers are using 60% of their quota? Does this mean 100% of the available capacity is being used? Cloud capacity planning also directly effects things like your SLA's and Q0S. Regardless of your platform, it's never good idea to use 100% of your available capacity nor should you. So determining the optimal capacity and having away to monitor it is going to be a crucial aspect in managing your cloud infrastructure.
I believe to fully answer the capacity question you must first determine your ideal customer. Determine where your sweet spot is, who you're going after (the low end, high end, commodity or niche markets). This will greatly help you determine your customer's capacity requirements. I'm also realistic, there is no one size fits all approach. For the most part, Cloud Computing is a best guess game, there are no best practices, architectural guidelines or practical references for you to base your deployment on. What it comes down to to is experience. The more of these we do the better we can plan. This is the value that companies such as Enomaly and the new crop of cloud computing consultants bring. What I find interesting is the more cloud computing as a service model is being adopted by hosting firms, the more these hosters are increasingly coming to us not only for our cloud infrastructure platform, but to help them navigate though a scary new world of cloud capacity planning.
Thursday, September 17, 2009
Autoscaling in the Cloud with PubSubHubbub
Lately I've been really intrigued by the PubSubHubbub protocol (PuSH) and its potential use as an intercloud communication protocol for monitoring and auto scaling your external cloud or internal infrastructure (or both).
For those of you not familiar with PuSH, it is a simple, open, server-to-server web-hook-based extension to Atom (and RSS) pubsub (publish/subscribe) protocol. Servers communicating via the PubSubHubbub protocol can get near-instant notifications (via webhook callbacks) when a topic (feed URL) they're interested in is updated.
In a post to Techcrunch Josh Fraser described PuSH saying "Currently, getting updates on the web requires constant polling. Subscribers are forced to act like nagging children asking, “Are we there yet?” Subscribers must constantly ping the publisher to ask if there are new updates even if the answer is “no” 99% of the time. This is terribly inefficient, wastes resources, and makes it incredibly hard to find new content in as soon as it appears. Both protocols flip the current model on its head so that updates are event driven rather than request driven. By that I mean that both protocols eliminate the need for polling by essentially telling subscribers, “Don’t ask us if there’s anything new. We’ll tell you.”"
Recently it occured to me that PuSH seems ideally suited as a low cost (free) decentralized notification system similar to Amazon's CloudWatch service. Amazon's CloudWatch is a web service that provides monitoring for AWS cloud resources, such as Amazon EC2 . It provides customers with visibility into resource utilization, operational performance, and overall demand patterns—including metrics such as CPU utilization, disk reads and writes, and network traffic. Amazon offers a the service at a rate of $0.015 per hour for each Amazon EC2 instance you monitor or about $18/day for a 50 node EC2 cluster. Yes it's cheap, but this approach is even cheaper and works across both existing internal infrastructure as well as cloud based IaaS such as Amazon EC2 Enomaly ECP, VMware, etc.
Below is a rough outline of how you might use PuSH as a basis for monitoring and scaling your cloud infrastructure.
Step 1
Step 2
Step 3
Step 4
Step 5
The possibilities are quite interesting to say the least.
For those of you not familiar with PuSH, it is a simple, open, server-to-server web-hook-based extension to Atom (and RSS) pubsub (publish/subscribe) protocol. Servers communicating via the PubSubHubbub protocol can get near-instant notifications (via webhook callbacks) when a topic (feed URL) they're interested in is updated.
In a post to Techcrunch Josh Fraser described PuSH saying "Currently, getting updates on the web requires constant polling. Subscribers are forced to act like nagging children asking, “Are we there yet?” Subscribers must constantly ping the publisher to ask if there are new updates even if the answer is “no” 99% of the time. This is terribly inefficient, wastes resources, and makes it incredibly hard to find new content in as soon as it appears. Both protocols flip the current model on its head so that updates are event driven rather than request driven. By that I mean that both protocols eliminate the need for polling by essentially telling subscribers, “Don’t ask us if there’s anything new. We’ll tell you.”"
Recently it occured to me that PuSH seems ideally suited as a low cost (free) decentralized notification system similar to Amazon's CloudWatch service. Amazon's CloudWatch is a web service that provides monitoring for AWS cloud resources, such as Amazon EC2 . It provides customers with visibility into resource utilization, operational performance, and overall demand patterns—including metrics such as CPU utilization, disk reads and writes, and network traffic. Amazon offers a the service at a rate of $0.015 per hour for each Amazon EC2 instance you monitor or about $18/day for a 50 node EC2 cluster. Yes it's cheap, but this approach is even cheaper and works across both existing internal infrastructure as well as cloud based IaaS such as Amazon EC2 Enomaly ECP, VMware, etc.
Below is a rough outline of how you might use PuSH as a basis for monitoring and scaling your cloud infrastructure.
Step 1
- Find a cluster monitor that supports a RSS or Atom output. My recommendation is Ganglia, a scalable distributed monitoring system targeted at federations of clusters. Ganglia includes the option of an RSS output for notification / syndication of system metrics such as load, i/o, dead machines, etc.
Step 2
- Create a feed URL (a "topic") that declares its Hub server(s) using an Atom or RSS XML file, via . (Atom and RssFeeds are supported) Topic's could include new machines, dead machines, 5 min average load, average network usage or any other system metric you deem valuable. The hub(s) can be run by the publisher of the feed, or can be a community hub that anybody can use.
Step 3
- A subscriber (a server or application that's interested in a topic), initially fetches the RSS or Atom URL and requests to the feed's hub(s) and subscribes to any subsequent updates pushed from it. Basically being notified upon certain changes. A subscriber could be a system administration tool such as Puppet that automatically adjusts based on near realtime notifications sent over the PubSubHubbub protocol.
Step 4
- When the Publisher (Load Monitor) next updates the Topic URL (i.e. Cluster ABC Load Average), the publisher pings the Hub(s) saying that there's an update.
Step 5
- The hub efficiently fetches the published feed and multicasts the new/changed content out to all registered subscribers where the subscribers then automatically can scale or adapt the infrastructure. Think of announcing a dead server to a cluster of hundreds of slaves. Or the addition of a new server.
The possibilities are quite interesting to say the least.
Tuesday, September 15, 2009
Is Privacy in The Cloud an Illusion?
With the announcement today that Adobe is acquiring Omniture, one of the largest web analytics firms -- something occurred to me. This is probably obvious to most, but the move to cloud based services has some pretty big potential ramifications when it comes to privacy and risks in unknowingly agreeing to the use of your private information being data mined. The Adobe Omniture deal makes this very apparent. More then ever, your privacy is becoming an illusion.
Like it or not when it comes to terms of use and privacy policies, most people don't read them. I'm a little bit of nut when it comes to them, but I fear I am in a minority. I also realize that when it comes to free and or low cost cloud services, you are typically asked to give up some privacy in return for the service. After all nothing is truly free. So the question now becomes how much of personal information should I be prepared to give away, be it for using a free cloud service or even for a paid service. What is an acceptable amount? None or some?
For some applications, such this blog or even some social networking application the idea of giving away some personal information doesn't appear to be a problem for most. Think of a targeted ad in facebook or a Google search. But what about when it comes to other more "grey" areas such as a cloud based document / content management system, email or CRM or other various business applications. The idea of unknowingly giving way personal information becomes a horrifying thought. Making it worse, you may never even realize it's happening. And who can blame you for being scared, I don't have time to read 50 page terms of usage and other various click wrapped user agreements.
So my question; is the Omniture deal just the tip of the privacy iceberg, and if so, how can we steer clear of any potential problems today?![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-id=5f0847e7-110c-49df-bdfd-ffe94930fcba)
Like it or not when it comes to terms of use and privacy policies, most people don't read them. I'm a little bit of nut when it comes to them, but I fear I am in a minority. I also realize that when it comes to free and or low cost cloud services, you are typically asked to give up some privacy in return for the service. After all nothing is truly free. So the question now becomes how much of personal information should I be prepared to give away, be it for using a free cloud service or even for a paid service. What is an acceptable amount? None or some?
For some applications, such this blog or even some social networking application the idea of giving away some personal information doesn't appear to be a problem for most. Think of a targeted ad in facebook or a Google search. But what about when it comes to other more "grey" areas such as a cloud based document / content management system, email or CRM or other various business applications. The idea of unknowingly giving way personal information becomes a horrifying thought. Making it worse, you may never even realize it's happening. And who can blame you for being scared, I don't have time to read 50 page terms of usage and other various click wrapped user agreements.
So my question; is the Omniture deal just the tip of the privacy iceberg, and if so, how can we steer clear of any potential problems today?
US Federal Government Launches Apps.Gov
Big news on the federal government cloud computing initiative front today with the launch of Apps.Gov. The site outlines several cloud service areas including business Apps, Productivity Apps, Cloud IT Services and Social Media Apps. What I found most interesting was upon first glance the vast majority of the services offered were from salesforce.com and a few from Google. Searches for Microsoft, IBM and Amazon resulted in no results. Also notable is the social media section which includes a few interesting choices including Scribd and SlideShare, yet none the major social media players are included.
As an infrastructure guy, the coming soon section for Cloud IT Services was particularly intriguing outling several cloud related infrastructure services that will be coming in the near future. Those outlined include;
One question I had was how these cloud computing services are provisioned using Apps.gov. The FAQ sheds a little more light on this saying: "A strategic assessment as to how your agency can benefit by using cloud computing services should be conducted. Browse Apps.gov to view the cloud services that are available. Services will continuously be added to Apps.gov. Business and Productivity applications (various cloud software as a service) and Cloud IT Infrastructure as a Service (cloud storage, hosting, and virtual machines) in most cases are offered as a monthly or even hourly use service. Billing for these services is typically monthly, based upon use, and may require close monitoring of your monthly purchase card spending limits. Since cloud offerings under Business and Productivity Applications as well as Cloud IT Services are products and services currently offered under GSA Multiple Award Schedule contracts, ordering activities are to use the procedures in Federal Acquisition Regulation (FAR) 8.405-1 where a Statement of Work (SOW) is not required. Ordering activities shall use the procedures in Federal Acquisition Regulation (FAR) 8.405-2 when ordering Schedule contract services requiring a Statement of Work."
Notably lacking on the site was how to get your cloud service included in the App Store, let's hope that this App Store will soon be opened up to a broader group, because it currently looks like a Salesforce / Google store.![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-id=b38db22a-324a-4963-83a2-262632805c1f)
As an infrastructure guy, the coming soon section for Cloud IT Services was particularly intriguing outling several cloud related infrastructure services that will be coming in the near future. Those outlined include;
Cloud storage
Get scalable storage of your data on the cloud rather than on your own dedicated servers.
Software development
Software development tools available on the cloud.
Virtual machines
The processing power that you need for your website or application on the cloud.
Web hosting
Hosting of your web applications on the cloud - 24x7.
Get scalable storage of your data on the cloud rather than on your own dedicated servers.
Software development
Software development tools available on the cloud.
Virtual machines
The processing power that you need for your website or application on the cloud.
Web hosting
Hosting of your web applications on the cloud - 24x7.
One question I had was how these cloud computing services are provisioned using Apps.gov. The FAQ sheds a little more light on this saying: "A strategic assessment as to how your agency can benefit by using cloud computing services should be conducted. Browse Apps.gov to view the cloud services that are available. Services will continuously be added to Apps.gov. Business and Productivity applications (various cloud software as a service) and Cloud IT Infrastructure as a Service (cloud storage, hosting, and virtual machines) in most cases are offered as a monthly or even hourly use service. Billing for these services is typically monthly, based upon use, and may require close monitoring of your monthly purchase card spending limits. Since cloud offerings under Business and Productivity Applications as well as Cloud IT Services are products and services currently offered under GSA Multiple Award Schedule contracts, ordering activities are to use the procedures in Federal Acquisition Regulation (FAR) 8.405-1 where a Statement of Work (SOW) is not required. Ordering activities shall use the procedures in Federal Acquisition Regulation (FAR) 8.405-2 when ordering Schedule contract services requiring a Statement of Work."
Notably lacking on the site was how to get your cloud service included in the App Store, let's hope that this App Store will soon be opened up to a broader group, because it currently looks like a Salesforce / Google store.
Monday, September 14, 2009
What is an OpenCloud API?
When it comes to defining Cloud Computing I typically take the stance of "I know it when I see it". Although I'm half joking, being able to spot an Internet centric platform or infrastructure is fairly self evident for the most part. But when it comes to an "OpenCloud API" things get a little more difficult.
Lately it seems that everyone is releasing their own "OpenCloud API's", companies like GoGrid and Sun Microsystems were among the first to embrace this approach offering there API's under friendly open creative common licenses. The key aspect in most of these CC licensed API's is the requirement that attribution is given to the original author or company. Although personally I would argue that a CC license isn't completely open because of this attribution requirement, but at the end of the day it's probably open enough.
For some background, a Cloud API determines the vocabulary / taxonomy that a programmer needs employ when using a particular set of cloud services. To be clear, an API is only the documents and processes for the usage of a certain cloud API, without these there is no API. In a recent twitter post Simon Wardley said it this way, "Companies can't own APIs only the documentation, tools and processes (which are generic to the API)."
Generally there are three types of Cloud API's.
1. Blind API's - API's that don't tell you their restrictions. Amazon Web Services is the best example. (Personally I'd rather know what I can or can't do then not know at all)
2. Closed API's - API's that do tell you their restrictions. Google App Engine is a good example using a highly restrictive license. The Google terms state in section 7.2. that "you may not (and you may not permit anyone else to): (a) copy, modify, create a derivative work of, reverse engineer, decompile or otherwise attempt to extract the source code of the Google App Engine Software or any part thereof, unless this is expressly permitted" Which would make things like AppScale which is an open-source implementation of the Google AppEngine illegal under Google's terms of use.
3. OpenCloud API's - API's that generally let you do whatever you want as long as you give attribution. Rackspace, GoGrid and Sun are the best examples. A major issue facing a lot of these so called open API's is although you maybe free to remix and use the API, you could be limited by the use of a company's name or trademark. Making the attribution clause a potential mine field.
I'd like to also note that a sub branch of OpenCloud API's are Open Community API's such as the OGF's OCCI project. These community API's apply an open source model that allow anyone to get involved in the development and specifications of a Cloud API at little or no cost.
This brings us to what exactly is an OpenCloud API?
A Cloud API that is free of restrictions, be it usage, cost or otherwise.
Lately it seems that everyone is releasing their own "OpenCloud API's", companies like GoGrid and Sun Microsystems were among the first to embrace this approach offering there API's under friendly open creative common licenses. The key aspect in most of these CC licensed API's is the requirement that attribution is given to the original author or company. Although personally I would argue that a CC license isn't completely open because of this attribution requirement, but at the end of the day it's probably open enough.
For some background, a Cloud API determines the vocabulary / taxonomy that a programmer needs employ when using a particular set of cloud services. To be clear, an API is only the documents and processes for the usage of a certain cloud API, without these there is no API. In a recent twitter post Simon Wardley said it this way, "Companies can't own APIs only the documentation, tools and processes (which are generic to the API)."
Generally there are three types of Cloud API's.
1. Blind API's - API's that don't tell you their restrictions. Amazon Web Services is the best example. (Personally I'd rather know what I can or can't do then not know at all)
2. Closed API's - API's that do tell you their restrictions. Google App Engine is a good example using a highly restrictive license. The Google terms state in section 7.2. that "you may not (and you may not permit anyone else to): (a) copy, modify, create a derivative work of, reverse engineer, decompile or otherwise attempt to extract the source code of the Google App Engine Software or any part thereof, unless this is expressly permitted" Which would make things like AppScale which is an open-source implementation of the Google AppEngine illegal under Google's terms of use.
3. OpenCloud API's - API's that generally let you do whatever you want as long as you give attribution. Rackspace, GoGrid and Sun are the best examples. A major issue facing a lot of these so called open API's is although you maybe free to remix and use the API, you could be limited by the use of a company's name or trademark. Making the attribution clause a potential mine field.
I'd like to also note that a sub branch of OpenCloud API's are Open Community API's such as the OGF's OCCI project. These community API's apply an open source model that allow anyone to get involved in the development and specifications of a Cloud API at little or no cost.
This brings us to what exactly is an OpenCloud API?
A Cloud API that is free of restrictions, be it usage, cost or otherwise.
Friday, September 11, 2009
Governmental Cloud Interoperability on The Microsoft Cloud
Interesting post over at the interoperability @ Microsoft blog on viewing public government data with Windows Azure and PHP. The post outlines a functional example of a governmental cloud interoperability scenario using REST.
The demo is part of Microsoft's Open Government Data Initiative (OGDI) a cloud-based collection of software assets that enables publicly available government data to be easily accessible. Using open standards and application programming interfaces (API), developers and government agencies can retrieve the data programmatically for use in new and innovative online applications, or mashups.
The scenario uses publicly available government data sets that have been loaded into Windows Azure Storage, and the OGDI team built a data service that exposes the data through REST web services, returning data by default in the Atom Publishing Protocol format. The OGDI application uses ADO.NET Data Services to expose the data. On the diagram below you see the list of available data sets: http://ogdi.cloudapp.net/v1/dc.
This list is then accessed by the data browser web application built in PHP. To build the PHP applications the Toolkit for PHP with ADO.NET Data Services was used by simply generating the PHP proxy classes that would match the data sets exposed through REST at this URI: http://ogdi.cloudapp.net/v1/dc.

Trying out the sample application
The PHP Data browser sample application is deployed on Windows Azure. Although it is not required and it could be deployed on any PHP compatible hosting environment, this sample application showcases a PHP application running on Azure. You can view or download the source of this sample from the demo site: http://ogdiphpsample.cloudapp.net/
The OGDI Service demonstrates some of the possibilities of the Azure platform and you can try the OGDI interactive SDK http://ogdisdk.cloudapp.net to understand how it works, as it features a similar data browser developed in .NET.
![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-id=6ebefe2e-a161-4967-9c85-40cba6fd1031)
Thursday, September 10, 2009
Facebook Open Sources FriendFeed
Interesting developments today in the scalable real time web front. In a rather unexpected move, Facebook has released a project called Tornado -- an open source version of the scalable, non-blocking web server and and tools that power FriendFeed.
In a blog post from Facebook Director of Products, Bret Taylor he describes the project in three parts.
Very cool. Check out the announcement on the Facebook Developer Blog or you can download Tornado at tornadoweb.org.
-- Update --
I also just found this a script called s3server.py, an implementation of an S3-like storage server based on local files. Useful to test features that will eventually run on S3, or if you want torun something locally that was once running on S3.
In a blog post from Facebook Director of Products, Bret Taylor he describes the project in three parts.
All the basic site building blocks - Tornado comes with built-in support for a lot of the most difficult and tedious aspects of web development, including templates, signed cookies, user authentication, localization, aggressive static file caching, cross-site request forgery protection, and third party authentication like Facebook Connect. You only need to use the features you want, and it is easy to mix and match Tornado with other frameworks.
Real-time services - Tornado supports large numbers of concurrent connections. It is easy to write real-time services via long polling or HTTP streaming with Tornado. Every active user of FriendFeed maintains an open connection to FriendFeed's servers.
High performance - Tornado is pretty fast relative to most Python web frameworks. We ran some simple load tests against some other popular Python frameworks, and Tornado's baseline throughput was over four times higher than the other frameworks:
Very cool. Check out the announcement on the Facebook Developer Blog or you can download Tornado at tornadoweb.org.
-- Update --
I also just found this a script called s3server.py, an implementation of an S3-like storage server based on local files. Useful to test features that will eventually run on S3, or if you want torun something locally that was once running on S3.
It doesn't support all the features of S3, but it does work with the standard S3 client for the most basic semantics.
To use the standard S3 client with this module:
To use the standard S3 client with this module:
c = S3.AWSAuthConnection("", "", server="localhost", port=8888,is_secure=False)c.create_bucket("mybucket")c.put("mybucket", "mykey", "a value")print c.get("mybucket", "mykey").body"""
Wednesday, September 9, 2009
The District of Columbia Launches AppStore.dc.gov
The District of Columbia (Washington D.C) has launched one of the first live examples of a Government AppStore at appstore.dc.gov. The site features a series of cloud applications built using various DC government data feeds created by both DC government agencies and by individuals/companies.
The site includes a directory of both governmental and non governmental applications listed by category including Education, Public Safety, Economic Development, Infrastructure, Government Operations, Health and Human Services, and About DC
Below are some of the featured apps;
Check out the site at AppStore.dc.gov
The site includes a directory of both governmental and non governmental applications listed by category including Education, Public Safety, Economic Development, Infrastructure, Government Operations, Health and Human Services, and About DC
Below are some of the featured apps;
| | DC Wi-Fi Hot Spot Map Use the map to find a Wi-Fi hot spot and display information about it. |
| | CapStat Mapping Application DC Government operational data on the map. |
| | Business License Verification You can use this website to check to see if some types of businesses have valid licenses |
| | Summary Reports Summary reports based on operational data provided by DCRA, DDOT, MPD, OTR and the Citywide Call Center. |
| | DC Data Catalog Access to DC Government Data |
| | Emergency Information Center Use maps to help prepare for an emergency. |
| | DC Police Crime Mapping The Police Department's crime mapping application provides a comprehensive resource for information on crimes throughout the District of Columbia. |
| | DC Atlas Provides detailed maps with GIS functionality. Please turn off popup blockers while using DC Atlas. |
| | Property Quest An easy way to view a wide range of site-related information, especially information on historic resources. |
Check out the site at AppStore.dc.gov
Tuesday, September 8, 2009
CloudLoop - Universal Cloud Storage API
I'm still digging through a backlog of news & links sent to me during from my vacation. One of which is an interesting new project announced a couple weeks ago called CloudLoop. The project is described as a universal, open-source Java API and command-line tool for cloud storage, which lets you store, manage, and sync your data between all major providers.
According to the announcement Cloudloop aims to solve cloud storage related problems by putting a layer in between your application and its storage provider. It gives you one simple storage interface that supports a full directory structure and common filesystem-like operations (e.g. mv, cp, ls, etc).
The project currently supports Amazon S3, Nirvanix, Eucalyptus Walrus, Rackspace CloudFiles, Sun Cloud, with support coming soon for Microsoft Azure, EMC Atmos, Aspen, Diomede storage clouds.
Key futures include;
![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-id=8bc0ad97-4f18-448a-94a3-086802b4246a)
According to the announcement Cloudloop aims to solve cloud storage related problems by putting a layer in between your application and its storage provider. It gives you one simple storage interface that supports a full directory structure and common filesystem-like operations (e.g. mv, cp, ls, etc).
The project currently supports Amazon S3, Nirvanix, Eucalyptus Walrus, Rackspace CloudFiles, Sun Cloud, with support coming soon for Microsoft Azure, EMC Atmos, Aspen, Diomede storage clouds.
Key futures include;
Sync your data to multiple providers, so if your primary provider goes down you will still be able to access your data.Check out the project at www.cloudloop.com
Handles all the messy plumbing that comes with cloud storage, such as retry logic, authentication, and differences in vendor API's.
Makes switching between storage providers really easy. there are no code changes required to move to a new provider.
Lets you organize your data with a standard directory structure, rather than key-value systems offered by most providers.
Gives you a powerful unix-like command line interface for managing your data and configuring applications that use the cloudloop API.
VMware Releases vCloud API Under "Open" License
For anyone interested, VMware has launched their Vcloud API specification. They describe their new "open" vCloud API as an interface for providing and consuming virtual resources from the cloud. It enables deploying and managing virtualized workloads in internal and external clouds. The vCloud API allows for upload and download of vApps along with their instantiation, deployment and operation.
According to the vCloud FAQ, the API does not expose any aspect of the physical infrastructure (servers, storage, networks) or how the physical infrastructure is virtualized. In a cloud service only virtual forms of the infrastructure can be exposed through the API. The pure virtual nature of the API also helps make the API simple to use and implement
I also found this tidbit interesting. For a cloud service to be multi-tenant, both its API and its implementation must support multi-tenancy. The pure virtual nature of the vCloud API enables it to be multi-tenant. Each cloud customer, or tentant, can only see its own set of virtual resources while having no means to address the shared underlying physical resources. This kind of isolation between tenants is analogous to the isolation between processes in a conventional OS achieved through the use of virtual memory: each process sees a continuous memory address space for its own use, but cannot directly address the underlying physical memory or the virtual memory of another process. Just like the virtual memory sub-system of a conventional OS in cooperation with its platform APIs works to achieve isolation between processes, in the same manner the cloud service implementation together with the vCloud API can support multi-tenancy.
Finally, the vCloud API Specification and schema definition files are being released under a permissive (MIT like) license - Developers and service providers are free to make use of the API under a royalty free license that allows for extension. VMware copyright needs to be included in any redestribution of the API. See specific details on the license terms.
vCloud Hightlights
According to the vCloud FAQ, the API does not expose any aspect of the physical infrastructure (servers, storage, networks) or how the physical infrastructure is virtualized. In a cloud service only virtual forms of the infrastructure can be exposed through the API. The pure virtual nature of the API also helps make the API simple to use and implement
I also found this tidbit interesting. For a cloud service to be multi-tenant, both its API and its implementation must support multi-tenancy. The pure virtual nature of the vCloud API enables it to be multi-tenant. Each cloud customer, or tentant, can only see its own set of virtual resources while having no means to address the shared underlying physical resources. This kind of isolation between tenants is analogous to the isolation between processes in a conventional OS achieved through the use of virtual memory: each process sees a continuous memory address space for its own use, but cannot directly address the underlying physical memory or the virtual memory of another process. Just like the virtual memory sub-system of a conventional OS in cooperation with its platform APIs works to achieve isolation between processes, in the same manner the cloud service implementation together with the vCloud API can support multi-tenancy.
Finally, the vCloud API Specification and schema definition files are being released under a permissive (MIT like) license - Developers and service providers are free to make use of the API under a royalty free license that allows for extension. VMware copyright needs to be included in any redestribution of the API. See specific details on the license terms.
vCloud Hightlights
- RESTful with full programmatic control
- OVF standards based
- Platform independent
- Pure virtual
- Supports multi-tenancy
An Internet Computing Definition
I thought I'd try and interesting experiment by preforming a find & replace of the word "Cloud" with the word "Internet" using the Draft NIST Working definition of Cloud Computing. The results sheds some interesting light on some of the key problems facing the term cloud computing and how it's defined. Next time you're reading a cloud article, try replacing the word cloud with Internet and see what happens.
An Internet Computing Definition
An Internet Computing Definition
Saturday, September 5, 2009
One Cloud Standard to Rule them All
Lots of discussion recently on the the topic of Cloud standards and a potential Cloud standards war emerging. Thought I'd give you a quick run down.
In an article written by Tom Nolle for Internet Evolution he asks if Multiple Standards Could Spoil Cloud Computing. In the post he says " too many standards are worse than no standards at all, because these efforts can stifle innovation and even implementation. In the case of cloud computing, there’s also the big question of whether standards being pushed for private clouds will end up contaminating the successful Internet model of cloud computing."
Tom also gives some love to my Unified Cloud Interface concept saying "The best hope for a unification is the Cloud Computing Interoperability Forum. Its Unified Cloud Architecture tackles standards by making public cloud computing interoperable. Their map of cloud computing shows the leading public cloud providers and a proposed Unified Cloud Interface that the body defines, with a joking reference to Tolkien’s Lord of the Rings, as “One API to Rule them All". So then, why not have that “One API” rule private clouds, too? A single top-down vision of cloud computing for public and private clouds has to be a better approach." -- amen brotha.
(As a side note, I'm still committed to the concept of Semantic Cloud Abstraction and the Unified Cloud Interface Project (UCI), but lack the time to do much with it given all my various commitments. So if you're interested in helping do something more around the concept of semantic cloud API's, please feel free to get in touch. Currently I would describe the UCI as a science experiment at best.)
Elsewhere on the standards front, on Friday the OpenNebula project announced that they had made available a prototype implementation of the OCCI draft specification. In case you're not familar with OCCI, it's a simple open APIspecification for remote management of cloud computing infrastructures focused on multicloud interoperability. In the note to the OCCI mailing list they stated that they believe that it is important to have an implementation in order to demo the standard, which they think will provide value by being able to show people how the standard will function in a real world environment. The prototype includes a server implementation, client command for using the service and enabling access to the full functionality of the OCCI interface.
Some other interesting recent cloud standards commentary includes a post by Simon Wardley with an assertion that a standards war is now in full swing. In the post Wardley outlines several considerations for cloud standards including;
Personally I would say that at the end of the day, cloud standards seem to have little to do with customer requirements but instead more to do with marketeering and positioning for market dominance. If there truly is a cloud standards war emerging then the way it will be won will be based solely on the standard / platform with the broadest adoption. The technology (API, Platform, etc) with the broadest market penetration will ultimately win -- this is a certainty. Although personally I would prefer to see the "most open" and interoperable approach win, lets be realistic, the winner will most likely be the one with the largest share of cloud computing related revenue.
In an article written by Tom Nolle for Internet Evolution he asks if Multiple Standards Could Spoil Cloud Computing. In the post he says " too many standards are worse than no standards at all, because these efforts can stifle innovation and even implementation. In the case of cloud computing, there’s also the big question of whether standards being pushed for private clouds will end up contaminating the successful Internet model of cloud computing."
Tom also gives some love to my Unified Cloud Interface concept saying "The best hope for a unification is the Cloud Computing Interoperability Forum. Its Unified Cloud Architecture tackles standards by making public cloud computing interoperable. Their map of cloud computing shows the leading public cloud providers and a proposed Unified Cloud Interface that the body defines, with a joking reference to Tolkien’s Lord of the Rings, as “One API to Rule them All". So then, why not have that “One API” rule private clouds, too? A single top-down vision of cloud computing for public and private clouds has to be a better approach." -- amen brotha.
(As a side note, I'm still committed to the concept of Semantic Cloud Abstraction and the Unified Cloud Interface Project (UCI), but lack the time to do much with it given all my various commitments. So if you're interested in helping do something more around the concept of semantic cloud API's, please feel free to get in touch. Currently I would describe the UCI as a science experiment at best.)
Elsewhere on the standards front, on Friday the OpenNebula project announced that they had made available a prototype implementation of the OCCI draft specification. In case you're not familar with OCCI, it's a simple open APIspecification for remote management of cloud computing infrastructures focused on multicloud interoperability. In the note to the OCCI mailing list they stated that they believe that it is important to have an implementation in order to demo the standard, which they think will provide value by being able to show people how the standard will function in a real world environment. The prototype includes a server implementation, client command for using the service and enabling access to the full functionality of the OCCI interface.
Some other interesting recent cloud standards commentary includes a post by Simon Wardley with an assertion that a standards war is now in full swing. In the post Wardley outlines several considerations for cloud standards including;
- A specification can be controlled, influenced and directed more easily than an open source project.
- A specification can easily be exceeded providing mechanisms of lock-in whilst still retaining compliance to a 'standard'.
- A specification needs to be implemented and depending upon the size and complexity of the 'standard' this can create significant adoption barriers to having multiple implementations.
- Open source reference models provide a rapid means of implementing a 'standard' and hence encourage adoption.
- Open source reference models provide a mechanism for testing the compliance of any proprietary re-implementation.
- Adoption and becoming de facto are key to winning this war.
Personally I would say that at the end of the day, cloud standards seem to have little to do with customer requirements but instead more to do with marketeering and positioning for market dominance. If there truly is a cloud standards war emerging then the way it will be won will be based solely on the standard / platform with the broadest adoption. The technology (API, Platform, etc) with the broadest market penetration will ultimately win -- this is a certainty. Although personally I would prefer to see the "most open" and interoperable approach win, lets be realistic, the winner will most likely be the one with the largest share of cloud computing related revenue.
Friday, September 4, 2009
Announcing The Global Governmental Cloud Computing Roundtable
I am happy to announce my involvement as both instigator and moderator in an upcoming roundtable discussion on Global Governmental Cloud Computing coordinated by Foreign Affairs and International Trade Canada (DFAIT) and GTEC 2009 on October 6th in Ottawa, Canada.
The purpose of this by invitation meeting is to provide an international forum for leading government CIOs and CTOs to discuss the opportunities and challenges of implementing cloud computing solutions in the public sector. We expect a total of 20 to 25 leading international government representatives to participate in the discussions.
The sessions will be moderated by Reuven Cohen (me) and will include opening remarks by Jirka Danek, Chief Technology Officer, Public Works and Government Services Canada.
The event will include round table discussions among the foreign and Canadian government representatives focusing on the current cloud computing issues and themes such as the intersection of Cloud Computing, Cyber Defence Strategies and Governmental IT Services.
After the roundtable discussion there will be opportunity for bilateral meetings between delegates following the discussions including a networking dinner for participants and select industry invitees at one of Ottawa's finest restaurants.
(There is also opportunity for corporate sponsorship of the networking dinner afterward)
Open vSwitch Project Launches
Last week a new Open vSwitch project was launched with little fan fare and even less insight into who is behind the project. The project aims to create a multilayer virtual switch licensed under the open source Apache 2 license. At first glance the project looks very promising as the basis for creating distributed VLan and Virtual Private Clouds (VPC).
Before I go into the details of the project I will say I find it very interesting the complete lack of any insight into who is behind the project. The website doesn't include company or contact information. According to Alessandro Perilli at Virtualization.info the project is backed by Citrix. In Perilli's post he points to a twitter post written in June by Citrix CTO Simon Crosby where Crosby used his Twitter account to calls for beta testers of the “XenServer distributed virtual switch”. But I couldn't find any mention of Citrix in either the Open vSwitch website or the whois records for openvswitch.org. According to the whois lookup, the openvswitch.org website is registered to Martin Casado a student at Stanford with no affiliation with Citrix. Some further digging through the mailing archive I discovered the only real activity seems to be coming from a stealth company called Nicira.
Nicira describes themselves as "igniting a revolution in networking by creating a new software platform that will—for the first time—open up flexible, fine-grained control of wide area and virtual data center networks while dramatically lowering costs. The company was founded by networking research leaders from Stanford University and University of California at Berkeley, and is led by proven entrepreneurs in networking, security and virtualization. Nicira is advised and backed by recognized industry veterans, including Marc Andreessen, Diane Greene, Ben Horowitz and Andy Rachleff."
Back to why Open vSwitch is cool. According to the website the the goal of the project is to build a production quality switch for VM environments that supports standard management interfaces (e.g. NetFlow, RSPAN, ERSPAN, IOS-like CLI), and is open to programmatic extension and control. In addition, it is designed to support distribution across multiple physical servers similar to VMWare’s distributed vswitch or Cisco’s Nexus 1000v.
Before I go into the details of the project I will say I find it very interesting the complete lack of any insight into who is behind the project. The website doesn't include company or contact information. According to Alessandro Perilli at Virtualization.info the project is backed by Citrix. In Perilli's post he points to a twitter post written in June by Citrix CTO Simon Crosby where Crosby used his Twitter account to calls for beta testers of the “XenServer distributed virtual switch”. But I couldn't find any mention of Citrix in either the Open vSwitch website or the whois records for openvswitch.org. According to the whois lookup, the openvswitch.org website is registered to Martin Casado a student at Stanford with no affiliation with Citrix. Some further digging through the mailing archive I discovered the only real activity seems to be coming from a stealth company called Nicira.
Nicira describes themselves as "igniting a revolution in networking by creating a new software platform that will—for the first time—open up flexible, fine-grained control of wide area and virtual data center networks while dramatically lowering costs. The company was founded by networking research leaders from Stanford University and University of California at Berkeley, and is led by proven entrepreneurs in networking, security and virtualization. Nicira is advised and backed by recognized industry veterans, including Marc Andreessen, Diane Greene, Ben Horowitz and Andy Rachleff."
Back to why Open vSwitch is cool. According to the website the the goal of the project is to build a production quality switch for VM environments that supports standard management interfaces (e.g. NetFlow, RSPAN, ERSPAN, IOS-like CLI), and is open to programmatic extension and control. In addition, it is designed to support distribution across multiple physical servers similar to VMWare’s distributed vswitch or Cisco’s Nexus 1000v.
Open vSwitch currently supports multiple virtualization technologies including Xen/XenServer, KVM, and VirtualBox. The bulk of the code is written in platform-independent C and is easily ported to other environments.
The current release of Open vSwitch supports the following features:
- Visibility into inter-VM communication via NetFlow, SPAN, and RSPAN
- Standard 802.1Q VLAN model with trunking
- Per VM policing
- NIC bonding with source-MAC load balancing
- Kernel-based forwarding
- Support for OpenFlow
- Compatibility layer for the Linux bridging code
The following features are under development:
- User-space forwarding engine
- sFlow
- Compatibility layer for VDE
- Ethernet over GRE (for ERSPAN and virtual private network creation)
- Full L3 support + NAT
- Priority-based QoS
- More management interfaces (IOS-like CLI, SNMP, NetFlow)
- 802.1x/RADIUS
- Support for hardware acceleration (VMDQ, switching chips on SR-IOV NICs)
Thursday, September 3, 2009
Red Hat Unveils DeltaCloud Interoperability Broker
Earlier today, Red Hat announced a new DeltaCloud Interoperability API Framework with the goal of enabling an ecosystem of developers, tools, scripts, and applications which can interoperate across the public and private clouds. The open source project is built using Ruby as described as a cloud broker. The broker comes complete with drivers that map the API to both public clouds like EC2, and private virtualized clouds based on VMWare and Red Hat Enterprise Linux with integrated KVM. (Think of it like Red Hat's Libvirt project for cloud service providers)
Check out the project at deltacloud.org
---
My comments to Red Hat is -- very nicely done. I am looking forward to digging further.
Deltacloud gives you:
- REST API (simple, any-platform access)
- Support for EC2, RHEV-M; VMWare ESX, RackSpace coming soon
- Backward compatibility across versions, providing long-term stability for scripts, tools and applications
One level up, Deltacloud Portal provides a web UI in front of the Deltacloud API. With Deltacloud Portal, your users can:
- View image status and stats across clouds, all in one place
- Migrate instances from one cloud to another
- Manage images locally and provision them on any cloud
---
My comments to Red Hat is -- very nicely done. I am looking forward to digging further.
Defining Elastic Computing
Recently there has been a lot of talk about private clouds, public clouds and inter clouds and the problem in attempting to define their key attributes. The problem facing all the various cloud terms is the apparent lack of quantifiable characteristics. In contrast most other areas of technology include standard characteristics such as units of measurement that allows us to define specific quantifiable aspects. These aspects allow for the creation of complex models and formulas that enable a continued improvement and enhancement to the underlying platforms. I thought I'd briefly take a closer look at core concepts of elasticity and how it can be applied to cloud computing.
For a lot of companies looking at entering the cloud computing marketplace the lack of measurable capacity metrics has become a particular problem point. Currently trying to plan future resource & capacity requirements is an extremely difficult endeavor. Recent high profile cloud outages have made the need for proactive capacity measurement painfully clear. When it comes to scaling infrastructure it seems that a lot of cloud computing has come down to a best guess mentality. (Although companies like SOASTA have done a great job at attempting to solve this problem) At the end of the day these outages are generally because of the unforeseen aspects, namely the inability to adequately determine and measure an application or infrastructure's breaking point. For this reason I believe that going forward the concept of elasticity will quickly become one of the more important aspects when designing most modern cloud centric system architectures.
To give you some background, I've been pitch my vision for elastic computing for almost 6 years. (I'm told others have also used the term before me as well) Generally my theory for Elastic Computing is in the ability to apply a quantifiable methodology that allows for the basis of an adaptive introspection with in a real time hybrid cloud centric infrastructure. But this doesn't actually address the question of "What is Elastic Computing" for that we need to dig deeper.
First we must look at what "elasticity" is and how it can be applied. According wikipedia, "in physics, elasticity is the physical property of a material when it deforms under stress (e.g. external forces), but returns to its original shape when the stress is removed. The relative amount of deformation is called the strain." Similarly elasticity applied to computing can be thought as the amount of strain an application or infrastructure can withstand while either expanding or contracting to meet the demands place on it.
One of the best examples of elasticity can be found in economics where elasticity is described as "the ratio of the percent change in one variable to the percent change in another variable. It is a tool for measuring the responsiveness of a function to changes in parameters in a relative way. A typical example is analysis of the elasticity of substitution, price and wealth. Popular in economics, elasticity is an approach used among empiricists because it is independent of units and thus simplifies data analysis."
For me, the economic centric definition is the best way to apply elasticity to cloud computing. In this approach the main benefit is the ability to measure quantifiable capacity metrics using standard mathematical formulas such as "arc elasticity" -- a formula where the elasticity of one variable is measured with respect to another between two given points. The arc elasticity method of introspection is used when there is no general function for the relationship of two variables. (Think of an unknown or sudden increase in demand placed on an application or infrastructure) Therefore this formula provides the ability of to act as a predictive estimator for required system elasticity.
Wikipedia provides this economic example.
The quantifiable ability to manage, measure, predict and adapt responsiveness of an application based on real time demands placed on an infrastructure using a combination of local and remote computing resources.
For a lot of companies looking at entering the cloud computing marketplace the lack of measurable capacity metrics has become a particular problem point. Currently trying to plan future resource & capacity requirements is an extremely difficult endeavor. Recent high profile cloud outages have made the need for proactive capacity measurement painfully clear. When it comes to scaling infrastructure it seems that a lot of cloud computing has come down to a best guess mentality. (Although companies like SOASTA have done a great job at attempting to solve this problem) At the end of the day these outages are generally because of the unforeseen aspects, namely the inability to adequately determine and measure an application or infrastructure's breaking point. For this reason I believe that going forward the concept of elasticity will quickly become one of the more important aspects when designing most modern cloud centric system architectures.
To give you some background, I've been pitch my vision for elastic computing for almost 6 years. (I'm told others have also used the term before me as well) Generally my theory for Elastic Computing is in the ability to apply a quantifiable methodology that allows for the basis of an adaptive introspection with in a real time hybrid cloud centric infrastructure. But this doesn't actually address the question of "What is Elastic Computing" for that we need to dig deeper.
First we must look at what "elasticity" is and how it can be applied. According wikipedia, "in physics, elasticity is the physical property of a material when it deforms under stress (e.g. external forces), but returns to its original shape when the stress is removed. The relative amount of deformation is called the strain." Similarly elasticity applied to computing can be thought as the amount of strain an application or infrastructure can withstand while either expanding or contracting to meet the demands place on it.
One of the best examples of elasticity can be found in economics where elasticity is described as "the ratio of the percent change in one variable to the percent change in another variable. It is a tool for measuring the responsiveness of a function to changes in parameters in a relative way. A typical example is analysis of the elasticity of substitution, price and wealth. Popular in economics, elasticity is an approach used among empiricists because it is independent of units and thus simplifies data analysis."
For me, the economic centric definition is the best way to apply elasticity to cloud computing. In this approach the main benefit is the ability to measure quantifiable capacity metrics using standard mathematical formulas such as "arc elasticity" -- a formula where the elasticity of one variable is measured with respect to another between two given points. The arc elasticity method of introspection is used when there is no general function for the relationship of two variables. (Think of an unknown or sudden increase in demand placed on an application or infrastructure) Therefore this formula provides the ability of to act as a predictive estimator for required system elasticity.
Wikipedia provides this economic example.
The y arc elasticity of x is defined as:What is Elastic Computing?
where the percentage change is calculated relative to the midpoint

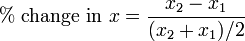

The quantifiable ability to manage, measure, predict and adapt responsiveness of an application based on real time demands placed on an infrastructure using a combination of local and remote computing resources.
Subscribe to:
Posts (Atom)
