
An interesting conference is happening Oct 5 and 6 in San Jose: Cloud Computing for Software Vendors (http://www.cloudfutures.com/usa) Every traditional software vendor I've spoken with sees the cloud coming and understands that it's a game-changer -- but until now they've all been on their own to come up with a "cloud strategy". And a lot of vendors have resorted to a knee-jerk "everything has to be SaaS" strategy. But that's not the only way to play -- just for one example, how about taking the existing product and making it more IaaS friendly? That's much easier in many ways (no new multi-tenancy issues, for example), but it tends to get overlooked.
Most software vendors aren't each other's competitors (e.g. a company that makes an accounting system doesn't compete with one that make geophysical modeling software), so why not leverage the community, and learn from each other? That's why this event is cool.
The organizers have also offered a discount code for Elastic Vapor readers -- if you register by web or phone, you can use the discount code ENOMALY for $200 off.
Disclaimer: Enomaly is one of the (many) vendors who will be giving a talk at this event.
Monday, August 31, 2009
Friday, August 28, 2009
Amazon's Virtual Private Cloud Is Everything and More
Well not to say I didn't see this coming over a year ago, Amazon has finally seen the light and rolled out a Virtual Private Cloud (VPC). Amazon describes their new Virtual Private Cloud in much the same way we do at Enomaly.
To recap, my original definition of a Virtual Private Cloud (VPC) is as a method for partitioning a public computing utility such as EC2 into quarantined virtual infrastructure. A VPC may encapsulate multiple local and remote resources to appear as a single homogeneous computing environment bridging the ability to securely utilize remote resources as part of an seamless global compute infrastructure. A core component of a VPC is a virtual private network (VPN) and or a virtual LAN (Vlan) in which some of the links between nodes are encrypted and carried by virtual switches.
According to the new VPC website, the "Amazon Virtual Private Cloud (Amazon VPC) is a secure and seamless bridge between a company’s existing IT infrastructure and the AWS cloud. Amazon VPC enables enterprises to connect their existing infrastructure to a set of isolated AWS compute resources via a Virtual Private Network (VPN) connection, and to extend their existing management capabilities such as security services, firewalls, and intrusion detection systems to include their AWS resources. Amazon VPC integrates today with Amazon EC2, and will integrate with other AWS services in the future."
VPC definitions and terminology aside the new service is important for a few reasons.
1. In a sense Amazon now has publicly admitted that private clouds do exist and the core differentiation is isolation (what I call quarantined cloud infrastructure), be it virtual or physical.
2. Greater Hybrid Cloud Interoperability & Standardized Network Security by enabling native VPN capabilities within their cloud infrastructure and command line tools. Amazon's VPC has added a much greater ability to interoperate with existing "standardized" VPN implementations including:
4. Lastly greater network partitioning, using Amazon's VPC, your EC2 instances are on your network. They can access or be accessed by other systems on the network as if they were local. As far as you are concerned, the EC2 instances are additional local network resources -- there is no NAT translation. A seemless bridge to the cloud.
In the blog post announcing the new service, I found their hybrid cloud use case particularly interesting; "Imagine the many ways that you can now combine your existing on-premise static resources with dynamic resources from the Amazon VPC. You can expand your corporate network on a permanent or temporary basis. You can get resources for short-term experiments and then leave the instances running if the experiment succeeds. You can establish instances for use as part of a DR (Disaster Recovery) effort. You can even test new applications, systems, and middleware components without disturbing your existing versions."
This was exactly the vision I outlined in my original post describing the VPC concept. I envisioned a VPC in which you are given the ability to virtualize the network giving it particular characteristics & appearance that match the demands as well as requirements of a given application deployed in the cloud regardless of whether it's local or remote. Amazon seems to realize that cloud computing isn't a big switch to cloud computing where suddenly you stop using existing "private" data centers. But instead the true opportunity for enterprise customers is a hybrid model where you use the cloud as needed, when needed, and if needed and not a second longer then needed.
I also can't help wondering how other cloud centric VPN providers such as CohesiveFT will respond to the rather sudden addition of VPN functionality, which in a single move makes third party VPN software obsolete or at very least not nearly as useful. (I feel your pain, remember ElasticDrive?) I am also curious to see how other IaaS providers such as Rackspace respond to the move, it may or may not be in their interest to offer compatible VPC services that allow for a secure interface between cloud service providers. The jury's still out on this one.
Let me also point out that although Amazon's new VPC service does greatly improve network security, it is not a silver bullet and the same core risks in the use of virtualization still remain. If Amazon's hypervisor is exploited, you'd never know it and unless your data never leaves an encrypted state it's at risk at one end point or another.
At Enomaly we have also been working on enhanced VPC functionality for our cloud service provider customers around the globe. For me this move by Amazon is a great endorsement of an idea we as well as others have been pushing for quite awhile.
On a side note, before you ask, Yes, I'm just glad I bought the VirtualPrivateCloud.com./.net/.org domain names when I wrote the original post. And yes, a place holder site and announcement is coming soon ;)
To recap, my original definition of a Virtual Private Cloud (VPC) is as a method for partitioning a public computing utility such as EC2 into quarantined virtual infrastructure. A VPC may encapsulate multiple local and remote resources to appear as a single homogeneous computing environment bridging the ability to securely utilize remote resources as part of an seamless global compute infrastructure. A core component of a VPC is a virtual private network (VPN) and or a virtual LAN (Vlan) in which some of the links between nodes are encrypted and carried by virtual switches.
According to the new VPC website, the "Amazon Virtual Private Cloud (Amazon VPC) is a secure and seamless bridge between a company’s existing IT infrastructure and the AWS cloud. Amazon VPC enables enterprises to connect their existing infrastructure to a set of isolated AWS compute resources via a Virtual Private Network (VPN) connection, and to extend their existing management capabilities such as security services, firewalls, and intrusion detection systems to include their AWS resources. Amazon VPC integrates today with Amazon EC2, and will integrate with other AWS services in the future."
VPC definitions and terminology aside the new service is important for a few reasons.
1. In a sense Amazon now has publicly admitted that private clouds do exist and the core differentiation is isolation (what I call quarantined cloud infrastructure), be it virtual or physical.
2. Greater Hybrid Cloud Interoperability & Standardized Network Security by enabling native VPN capabilities within their cloud infrastructure and command line tools. Amazon's VPC has added a much greater ability to interoperate with existing "standardized" VPN implementations including:
3. Further proof that Amazon is without any doubt going after the enterprise computing market where a VPN capability is arguably one of the most requested features.
- Ability to establish IKE Security Association using Pre-Shared Keys (RFC 2409).
- Ability to establish IPSec Security Associations in Tunnel mode (RFC 4301).
- Ability to utilize the AES 128-bit encryption function (RFC 3602).
- Ability to utilize the SHA-1 hashing function (RFC 2404).
- Ability to utilize Diffie-Hellman Perfect Forward Secrecy in “Group 2” mode (RFC 2409).
- Ability to establish Border Gateway Protocol (BGP) peerings (RFC 4271).
- Ability to utilize IPSec Dead Peer Detection (RFC 3706).
- Ability to adjust the Maximum Segment Size of TCP packets entering the VPN tunnel (RFC 4459).
- Ability to reset the “Don’t Fragment” flag on packets (RFC 791).
- Ability to fragment IP packets prior to encryption (RFC 4459).
- (Amazon also plans to support Software VPNs in the near future.)
4. Lastly greater network partitioning, using Amazon's VPC, your EC2 instances are on your network. They can access or be accessed by other systems on the network as if they were local. As far as you are concerned, the EC2 instances are additional local network resources -- there is no NAT translation. A seemless bridge to the cloud.
In the blog post announcing the new service, I found their hybrid cloud use case particularly interesting; "Imagine the many ways that you can now combine your existing on-premise static resources with dynamic resources from the Amazon VPC. You can expand your corporate network on a permanent or temporary basis. You can get resources for short-term experiments and then leave the instances running if the experiment succeeds. You can establish instances for use as part of a DR (Disaster Recovery) effort. You can even test new applications, systems, and middleware components without disturbing your existing versions."
This was exactly the vision I outlined in my original post describing the VPC concept. I envisioned a VPC in which you are given the ability to virtualize the network giving it particular characteristics & appearance that match the demands as well as requirements of a given application deployed in the cloud regardless of whether it's local or remote. Amazon seems to realize that cloud computing isn't a big switch to cloud computing where suddenly you stop using existing "private" data centers. But instead the true opportunity for enterprise customers is a hybrid model where you use the cloud as needed, when needed, and if needed and not a second longer then needed.
I also can't help wondering how other cloud centric VPN providers such as CohesiveFT will respond to the rather sudden addition of VPN functionality, which in a single move makes third party VPN software obsolete or at very least not nearly as useful. (I feel your pain, remember ElasticDrive?) I am also curious to see how other IaaS providers such as Rackspace respond to the move, it may or may not be in their interest to offer compatible VPC services that allow for a secure interface between cloud service providers. The jury's still out on this one.
Let me also point out that although Amazon's new VPC service does greatly improve network security, it is not a silver bullet and the same core risks in the use of virtualization still remain. If Amazon's hypervisor is exploited, you'd never know it and unless your data never leaves an encrypted state it's at risk at one end point or another.
At Enomaly we have also been working on enhanced VPC functionality for our cloud service provider customers around the globe. For me this move by Amazon is a great endorsement of an idea we as well as others have been pushing for quite awhile.
On a side note, before you ask, Yes, I'm just glad I bought the VirtualPrivateCloud.com./.net/.org domain names when I wrote the original post. And yes, a place holder site and announcement is coming soon ;)
Saturday, August 22, 2009
A Public Cloud by Any Other Name is Private
Over the last week I have been away on vacation so I've missed some recent debates among the clouderati. I'm home today before I leave for Europe tomorrow, before I leave I wanted to comment on these debates. In particular the one that started because of Appirio’s corporate blog post “Rise and Fall of the Private Cloud and the comments made by Hoff in response.
According to Hoff's post, the short and sweet, of Appirio’s stance on Private Cloud is as follows.
Let me boil down my view of what a private cloud is into the most simplistic terms possible. It's a point of view. Let me put it another way, imagine for a moment that Amazon had built their Elastic Compute Cloud with all the same characteristics of the current EC2 offering but instead of making it available for public usage, they only make it available internally? What would you call that? I'd call it a private cloud.
In a nutshell a private cloud is the attempt to build an Amazon or Google or even a Microsoft style web centric data center infrastructure in your own data center on your own equipment. For me, and the customers we typically deal with at Enomaly -- a private cloud is about applying the added benefits of elasticity, rapid scale (internal or external), resource efficiency and utilization flexibility that you gain by managing your infrastructure as a multi tenant service. So at the end of the day one person's public cloud is an others private cloud, it just depends on your point of view.![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-id=4e2cde9a-9851-4c2d-a856-d65c758677f4)
According to Hoff's post, the short and sweet, of Appirio’s stance on Private Cloud is as follows.
As Hoff always does, he cuts to the bone with his closing remarks.Here’s the rub: Private clouds are just an expensive data center with a fancy name. We predict that 2009 will represent the rise and fall of this over-hyped concept. Of course, virtualization, service-oriented architectures, and open standards are all great things for every company operating a data center to consider. But all this talk about “private clouds” is a distraction from the real news: the vast majority of companies shouldn’t need to worry about operating any sort of data center anymore, cloud-like or not.
It’s really silly to suggest that the only thing an enterprise will do is simply move “legacy applications as-is to a new and improved data center” without any enterprise modernization, any optimization or the ability to more efficiently migrate to new and improved applications as the agility, flexibility and mobility issues are tackled.
Let’s be real, Appirio is in the business of “Enabling enterprise adoption of on-demand for Salesforce.com and Google Enterprise” — two examples of externally hosted SaaS offerings that clearly aren’t aimed at enterprises who would otherwise be thinking about Private Cloud.
Let me boil down my view of what a private cloud is into the most simplistic terms possible. It's a point of view. Let me put it another way, imagine for a moment that Amazon had built their Elastic Compute Cloud with all the same characteristics of the current EC2 offering but instead of making it available for public usage, they only make it available internally? What would you call that? I'd call it a private cloud.
In a nutshell a private cloud is the attempt to build an Amazon or Google or even a Microsoft style web centric data center infrastructure in your own data center on your own equipment. For me, and the customers we typically deal with at Enomaly -- a private cloud is about applying the added benefits of elasticity, rapid scale (internal or external), resource efficiency and utilization flexibility that you gain by managing your infrastructure as a multi tenant service. So at the end of the day one person's public cloud is an others private cloud, it just depends on your point of view.
Updated Draft NIST Working Definition of Cloud Computing v15
National Institute of Standards and Technology, (NIST) Information Technology Laboratory has published an updated version of their Working Definition of Cloud Computing.
Draft NIST Working Definition of Cloud Computing v15
Original Doc is available here
![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-id=1ca64bfb-ad5a-40a2-bbe6-020968b6d6ac)
Draft NIST Working Definition of Cloud Computing v15
Original Doc is available here
Thursday, August 20, 2009
Fixing Major Linux Kernel Vulnerabilities in the Cloud
While I am away on vacation, I have invited Joel Wampler to be a guest author on the ElasticVapor Blog, hopefully something I will be doing more frequently in the future. Joel is a Systems Architect at Standing Cloud, Inc., a startup that will be soon launching software and services that facilitate application deployment and management for on-demand cloud services. In this post, he points out that last week's Linux kernel vulnerability has some extra implications for IaaS and infrastructure focused cloud computing as well as some simple steps to fix these vulnerabilities.
Issues like this are clear examples of something we at Enomaly have been saying for some time. Like it or not cloud computing brings unique security risks with it, which need to be specifically managed and mitigated. This latest Linux Kernel vulnerability is another prime example of the challenges facing cloud service providers and their customers. To help reduce this risk later this year Enomaly will deliver the first generation of our security technology, which will help customers to achieve a level of security in the cloud equivalent to what they have inside their data centers today.
Thank you Joel for taking the time to bring awareness to the new risks facing cloud users.
---
Last week, a Linux kernel vulnerability that allows for local privilege escalation through a NULL pointer dereference was announced. Many of the major Linux distributions are still working to provide updated kernels, and a few already have. Once updated kernels are released, applying the patches should be straightforward. But for systems running in the cloud, additional complexities and delays may arise.
Most providers of on-demand cloud servers require the use of custom kernels, which are tuned for the provider's specific virtualization implementation. These custom kernels significantly change the upgrade path, and may even affect the short-term workarounds provided by the upstream distribution.
For instance, the Ubuntu bug report for this issue states the following:
Ubuntu 8.04 and later have a default setting of 65536 in /proc/sys/vm/mmap_min_addr. When set, this issue is blocked.
However, if a system is running Ubuntu 8.04 on Amazon EC2, the underlying kernel is likely based on a Fedora Core 8 Xen kernel. This is one of the kernels Amazon provides to those who create boot images for their service, and most such images use this kernel regardless of the distribution running on top of it. Thus the default setting of 65536 cannot be relied upon; and worse, this proc setting does not even exist in the Fedora kernel, so there is no way to repair the image to match this workaround.
When a cloud provider does eventually provide updated kernels, applying them to running cloud servers will also present challenges that don't exist with bare iron. The upgrade method will vary greatly between providers. It could be as simple as contacting support and asking them to make the switch, or it could be a tedious process involving re-bundling and re-registering images. Whatever it may involve, it is certainly not as easy as just applying the latest kernel packages and rebooting.
Kernel bugs of this severity don't arise too often. But a cloud provider's custom kernel is the one piece of software that users of on-demand cloud servers cannot simply replace. This vulnerability sheds light on an area that hasn't been completely hashed out yet by on-demand providers; they need to be more proactive in both distributing information about kernel security issues, as well as documenting image and instance upgrade procedures once a fix is available.
As to this particular vulnerability, the workaround originally provided by RedHat and also by Ubuntu in their bug report, seems to be the most universal means of mitigation until new kernels are released (whether or not the server is in the cloud).
Simply enter the following at the command line as root:
cat > /etc/modprobe.d/mitigate-2692.
conf << EOM
install pppoe /bin/true
install pppox /bin/true
install sctp /bin/true
install bluetooth /bin/true
install irda /bin/true
install ax25 /bin/true
install x25 /bin/true
install ipx /bin/true
install appletalk /bin/true
EOM
This will prevent any modules known to be affected by the vulnerability from being loaded, which should prevent the exploit from being successful. Fortunately, most of these modules are not widely used on cloud servers. Of course, if your application requires one of these modules, you may need to find another mitigation or to run insecurely until other fixes are available.
Issues like this are clear examples of something we at Enomaly have been saying for some time. Like it or not cloud computing brings unique security risks with it, which need to be specifically managed and mitigated. This latest Linux Kernel vulnerability is another prime example of the challenges facing cloud service providers and their customers. To help reduce this risk later this year Enomaly will deliver the first generation of our security technology, which will help customers to achieve a level of security in the cloud equivalent to what they have inside their data centers today.
Thank you Joel for taking the time to bring awareness to the new risks facing cloud users.
---
Last week, a Linux kernel vulnerability that allows for local privilege escalation through a NULL pointer dereference was announced. Many of the major Linux distributions are still working to provide updated kernels, and a few already have. Once updated kernels are released, applying the patches should be straightforward. But for systems running in the cloud, additional complexities and delays may arise.
Most providers of on-demand cloud servers require the use of custom kernels, which are tuned for the provider's specific virtualization implementation. These custom kernels significantly change the upgrade path, and may even affect the short-term workarounds provided by the upstream distribution.
For instance, the Ubuntu bug report for this issue states the following:
Ubuntu 8.04 and later have a default setting of 65536 in /proc/sys/vm/mmap_min_addr. When set, this issue is blocked.
However, if a system is running Ubuntu 8.04 on Amazon EC2, the underlying kernel is likely based on a Fedora Core 8 Xen kernel. This is one of the kernels Amazon provides to those who create boot images for their service, and most such images use this kernel regardless of the distribution running on top of it. Thus the default setting of 65536 cannot be relied upon; and worse, this proc setting does not even exist in the Fedora kernel, so there is no way to repair the image to match this workaround.
When a cloud provider does eventually provide updated kernels, applying them to running cloud servers will also present challenges that don't exist with bare iron. The upgrade method will vary greatly between providers. It could be as simple as contacting support and asking them to make the switch, or it could be a tedious process involving re-bundling and re-registering images. Whatever it may involve, it is certainly not as easy as just applying the latest kernel packages and rebooting.
Kernel bugs of this severity don't arise too often. But a cloud provider's custom kernel is the one piece of software that users of on-demand cloud servers cannot simply replace. This vulnerability sheds light on an area that hasn't been completely hashed out yet by on-demand providers; they need to be more proactive in both distributing information about kernel security issues, as well as documenting image and instance upgrade procedures once a fix is available.
As to this particular vulnerability, the workaround originally provided by RedHat and also by Ubuntu in their bug report, seems to be the most universal means of mitigation until new kernels are released (whether or not the server is in the cloud).
Simply enter the following at the command line as root:
cat > /etc/modprobe.d/mitigate-2692.
conf << EOM
install pppoe /bin/true
install pppox /bin/true
install sctp /bin/true
install bluetooth /bin/true
install irda /bin/true
install ax25 /bin/true
install x25 /bin/true
install ipx /bin/true
install appletalk /bin/true
EOM
This will prevent any modules known to be affected by the vulnerability from being loaded, which should prevent the exploit from being successful. Fortunately, most of these modules are not widely used on cloud servers. Of course, if your application requires one of these modules, you may need to find another mitigation or to run insecurely until other fixes are available.
Friday, August 14, 2009
A Cloud Surge Protector
Chet Kapoor, CEO of Sonoa System used a very interesting analogy in a recent blog post. In the post he referrers to an article on wsj.com which argues that as the pace of change accelerates, trust becomes vital currency and we need rethink how we address technology.
![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-id=2bf6b130-9e80-43a9-a742-8029e34c92c9)
Kapoor draws parallels with what he says is happening within cloud computing and what he calls "the API economy". In particular, he asks "how do we control this increasingly out-of-control, interlinked world? His Answer? “online surge-protectors to stop run-ups and panics”
His comments of a cloud surge protect really struck a chord with me. If you think of a load balancer as an analogy for a traditional electrical surge protector, you really start to see the opportunity for cloud bursting within a modern data center used in much the same way you'd use a backup power supply or even a circuit breaker.
So here is my take on a cloud surge protector definition using the Wikipedia description of a traditional surge protector as my base.
A cloud surge protector (or cloud surge suppressor) is an appliance designed to protect computing infrastructure from sudden spikes in network & application demand. A cloud surge protector attempts to regulate the compute capacity supplied to an infrastructure by either blocking or by automatically redirecting requests to a third party cloud provider.
Amazon Adds Data Portability With New Import/Export Service
Amazon Web Service today announced a new AWS Import/Export feature. A potentially huge step forward for data portabilty when using the Amazon Cloud computing infrastructure.
In a recent post by AWS Evangelist, Jeff Barr outlined the new functionality stating that "using a workflow similar to the one you'd use to import data, you prepare a MANIFEST file, email it to us, receive a job identifier in return, and then send us one or more specially prepared storage devices. We'll take the devices, verify them against your manifest file, copy the data from one or more S3 buckets to your device(s) and ship them back to you."
Sign up here to get started with AWS Import/Export.
As always, nice work Amazon!
![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-id=d731b6f8-4d94-4d94-9889-5f2ae25513bf)
In a recent post by AWS Evangelist, Jeff Barr outlined the new functionality stating that "using a workflow similar to the one you'd use to import data, you prepare a MANIFEST file, email it to us, receive a job identifier in return, and then send us one or more specially prepared storage devices. We'll take the devices, verify them against your manifest file, copy the data from one or more S3 buckets to your device(s) and ship them back to you."

A "specially prepared" storage device contains a SIGNATURE file. The file uniquely identifies the Import/Export job and also authenticates your request.
You can use the new CREATE EXPORT PLAN email command to simplify the process of exporting a data set that won't fit on a single storage device. Given the block size, and the device capacity (either formatted or unformatted), the command returns a link to a zip file with a set of MANIFEST files inside.
You will be charged a fixed fee of $80.00 per device and $2.49 per hour for the time spent copying the data to your device. Normal charges for S3 requests also apply. There is no charge for bandwidth.
Barr also outlines several uses for this new feature including.
- Disaster Recovery - If your local storage fails or is destroyed, use the Export feature to retrieve your precious data.
- Data Retrieval - After creating a large data set (either by gathering it up or by computing it) in the cloud, use the Export feature to get a local copy.
- Data Distribution - Take a large data set, sell copies, and use the Export feature to take care of the distribution.
- Data Processing - Use the Import feature to load a large data set (yours or a customers') into the cloud, do some computationally intensive processing (e.g. de-duplication), and then get the data back using the Export feature.
| Available Internet Connection | Theoretical Min. Number of Days to Transfer 1TB at 80% Network Utilization | When to Consider AWS Import/Export? |
| T1 | 82 days | 100GB or more |
| 10Mbps | 13 days | 600GB or more |
| T3 | 3 days | 2TB or more |
| 100Mbps | 1 to 2 days | 5TB or more |
| 1000Mbps | Less than 1 day | 60TB or more |
Sign up here to get started with AWS Import/Export.
As always, nice work Amazon!
Humanless Computing
I wanted to do a quick post before I take off for the next couple weeks. I'll be at my cottage next week and in Venice Italy the following week speaking at a private business summit at a monastery in the heart of the city. Rough life, I know. As part of this gig they even agreed to fly out my wife and 7 month old son.
A few random thoughts before I leave. As we move more towards autonomic computing future, I think the greater test of a efficient fault tolerant infrastructure will be to measure the human factor in it's management or possibly the lack of it. I know that some may not like a future where computers and infrastructure no longer need humans to manage it, but the reality is we as human operators are the biggest single limiting factor when it comes to computing. So while I'm away, ponder this. The next big thing in computing may very well be humanless computing.
I'll leave you with this great presentation by Lew Tucker at Sun Microsystem where he theorizes applications that are entirely self-sufficient, where humans will be able to set boundaries, of course, but will no longer be needed to turn servers, or anything else for that matter, physically on or off.
![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-id=bba1186e-e9b8-454f-85b2-f7590b28bef8)
A few random thoughts before I leave. As we move more towards autonomic computing future, I think the greater test of a efficient fault tolerant infrastructure will be to measure the human factor in it's management or possibly the lack of it. I know that some may not like a future where computers and infrastructure no longer need humans to manage it, but the reality is we as human operators are the biggest single limiting factor when it comes to computing. So while I'm away, ponder this. The next big thing in computing may very well be humanless computing.
I'll leave you with this great presentation by Lew Tucker at Sun Microsystem where he theorizes applications that are entirely self-sufficient, where humans will be able to set boundaries, of course, but will no longer be needed to turn servers, or anything else for that matter, physically on or off.
Wednesday, August 12, 2009
Vivek Kundra Vindicated
Just a quick update from my previous post about Vivek Kundra being accused of being a phony. Turns out he's not and the only person who is looking like a phony is John C. Dvorak for not doing his homework.
In some quick detective work Om Malik said,
Dvorak is just flat-out wrong — or at least that was the gist of the conversation I just had with Kundra. He called back and said that it was clear that “someone was spinning partial truths.” He welcomed anyone to check with University of Maryland’s University College and said they will find that not only did he graduate from the University College, but also that he was adjunct faculty member.Nextgov.com writer Gautham Nagesh goes further
I'm glad this story turned out for the best. But I'm not sure if I'll ever believe anything Dvorak writes going forward.However, after a few phone calls I was able to verify that Kundra did receive a Master's degree in Information Systems Management from the University of Maryland University College in 2001. That seems to conform with his official bio, where it states he "holds a MS in Information Technology from the University of Maryland. -- Dvorak obviously doesn't think too highly about Kundra's qualifications for his job, or those of federal chief technology officer Aneesh Chopra. But I was able to verify Kundra's degree with just a few phone calls in under two hours. Dvorak's arguments for why Kundra and Chopra are not qualified for their posts would be more compelling if he didn't resort to unverified accusations to support them."
Monday, August 10, 2009
VMware Getting into PaaS with SpringSource Acquisition
Hot on the heals of SpringSource's recent acquisition of Hyperic, VMware today announced their intention to acquire SpringSource. At first glance this move may seem puzzling, why would VMware want to buy an open source enterprise application development platform? Could it be for Hyperic, an open source IT management platform? I doubt it. I'd say it's all about planning for the future, a future where the OS no longer matters, a future where all applications are built, deployed and consumed via the Internet. Yes folks, I'm talking about Platform as a Service.
According to the post by VMware CTO Steve Herrod, he states that since it's founding 11 years ago, VMware has focused on simplifying IT. More to the point saying "VMware has traditionally treated the applications and operating systems running within our virtual machines (VMs) as black boxes with relatively little knowledge about what they were doing."
Moreover I too believe that the operating system seems to get in the way more then it helps. Add in overly complex hyper-visors and you've got several layers too many of abstraction when we all know the real work gets done in the application layer. Everything else just subtracts from the end goal -- Building and deploying scalable applications which at the end of the day is the only reason to have any sort of IT infrastructure anyway.
VMware even has a nice picture to illustrate their the new PaaS initiative:
A few weeks ago Tom Lounibos, CEO of Soasta summed up the opportunity when asked "What's the future for Cloud "IaaS" vendors?"...he replied..."becoming "PaaS" vendors". So true
According to the post by VMware CTO Steve Herrod, he states that since it's founding 11 years ago, VMware has focused on simplifying IT. More to the point saying "VMware has traditionally treated the applications and operating systems running within our virtual machines (VMs) as black boxes with relatively little knowledge about what they were doing."
Moreover I too believe that the operating system seems to get in the way more then it helps. Add in overly complex hyper-visors and you've got several layers too many of abstraction when we all know the real work gets done in the application layer. Everything else just subtracts from the end goal -- Building and deploying scalable applications which at the end of the day is the only reason to have any sort of IT infrastructure anyway.
VMware even has a nice picture to illustrate their the new PaaS initiative:
The announcement goes on to outline "common goals for developers to easily build their applications and move from coding to production execution as seamlessly as possible… regardless of whether they will be deployed to a small internal datacenter for limited use or to a completely external cloud provider for much larger scale audiences (and the hopes of achieving Facebook application stardom!). This end state has a lot in common with what is today referred to as “platform as a service” (abbreviated PaaS). Salesforce.com’s Force.com and Google’s AppEngine are two of the best known examples of PaaS today."
A few weeks ago Tom Lounibos, CEO of Soasta summed up the opportunity when asked "What's the future for Cloud "IaaS" vendors?"...he replied..."becoming "PaaS" vendors". So true
Sunday, August 9, 2009
Waiting in the Cloud Queue
Which would you rather have? A compute job that gets done over a 12 hour period on a Supercomputer with the catch that you need to wait 7 days until the job actually runs? Or a job that runs over a 60 hour period on a lower performance public cloud infrastructure that can start immediately?
In a recent post Ian Foster asked just this saying "what if I don't care how fast my programs run, I simply want to run them as soon as possible? In that case, the relevant metric is not execution time but elapsed time from submission to the completion of execution. (In other words, the time that we must wait before execution starts becomes significant.)"
What I can't help wondering is whether cloud computing may be shifting the focus of high performance computing from the need for optimized peak utilization of a few very specific tasks to lower performance cloud platforms that can run a much broader set of diverse parallel tasks.
Or to put it another way, in those seven days while I wait for my traditional HPC job to get scheduled and completed, I could have been running dozens of similar jobs on lower performance public cloud infrastructures capable of running multiple variations of the original task in parallel.
In a sense this question perfectly illustrates the potential economies of scale cloud computing enables. (a long run concept that refers to reductions in unit cost as the size of a facility, or scale, increases) On a singular basis my job will take a significantly longer period of time to execute. But on the other hand, by using a public cloud there is siginificanly more capacity available to me, so I am able to do significantly more at a much lower cost per compute cycle in roughly the same time my original job was in the queue .![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-id=b94a55fc-a17b-40ff-ab66-5d73a688148f)
In a recent post Ian Foster asked just this saying "what if I don't care how fast my programs run, I simply want to run them as soon as possible? In that case, the relevant metric is not execution time but elapsed time from submission to the completion of execution. (In other words, the time that we must wait before execution starts becomes significant.)"
What I can't help wondering is whether cloud computing may be shifting the focus of high performance computing from the need for optimized peak utilization of a few very specific tasks to lower performance cloud platforms that can run a much broader set of diverse parallel tasks.
Or to put it another way, in those seven days while I wait for my traditional HPC job to get scheduled and completed, I could have been running dozens of similar jobs on lower performance public cloud infrastructures capable of running multiple variations of the original task in parallel.
In a sense this question perfectly illustrates the potential economies of scale cloud computing enables. (a long run concept that refers to reductions in unit cost as the size of a facility, or scale, increases) On a singular basis my job will take a significantly longer period of time to execute. But on the other hand, by using a public cloud there is siginificanly more capacity available to me, so I am able to do significantly more at a much lower cost per compute cycle in roughly the same time my original job was in the queue .
Friday, August 7, 2009
The Cyberwar Bait & Switch -- Blame Russia
First of all let me say I've suspected something fishy from the start of this latest social denial of service attack on various social networks. The more I dig the more it seems to have been committed & perpetrated by someone friendly to Georgia not Ruissia. I believe this for a couple reasons, #1 make Russia look bad, and #2 bring attention to conflict. More to the point this "cyberwar" was perpetrated for PR purposes only.
Let's start off by pointing out the obvious. Why would Russia want to bring attention to the Georgian conflict on the one year anniversary of the war? More-over if they were behind it, why would they attack just one person, effectively making this person a cyber martyr? It makes no sense. This is the last thing they would want to do. The first rule of war, cyber or traditional is not to empower your enemy. Which in a sense is exactly what happened. They made @cyxymu a kind of cyberwar superstar. If this attack was truly just on one person, I'm sure a more traditional means of elimination of said target would have been a heck of a lot easier to accomplish and would have made a lot less noise. This is especially true in Eastern Europe where people routinely go missing for a lot less. A traditional assassination would have gone completely unnoticed by the West. Instead we are to believe that a very public cyber attack on Twitter, Facebook and Google was orchestrated by the Russians. I'm not sold.
The tactics of the attack don't exactly scream covert Russian operation. They scream botnet for hire. Eastern European zombie networks have become a source of income for entire groups of cybercriminals. A basic botnet running out of eastern Europe for DDoS attacks, can run from $50 to a few thousands dollars depending on the size of the botnet and length of the attack. The most advanced using a fast flux botnet approach (the type most likely used). Anyone with a few bucks can hire their very own botnet and blame anyone they wish. Pointing the botnet at just one person (yourself) is a genius move if you blame someone else. Think of it as a cyberwar Bait & Switch.
If I were a betting man, I'd say that this attack was done using Multi-Stage BGP & DNS Attack Vector. My only real proof is a little common sense as well as the simple reason that a typical HTTP denial of service attack causes a spike in traffic not a drop as illustrated below.

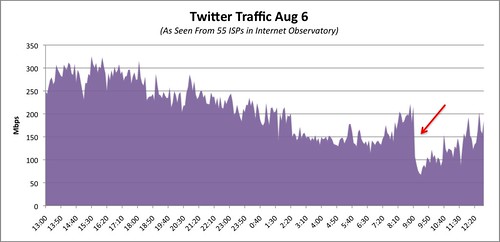
![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-id=5a7d376b-fc6b-414c-a45b-2b57328d16fa)
Let's start off by pointing out the obvious. Why would Russia want to bring attention to the Georgian conflict on the one year anniversary of the war? More-over if they were behind it, why would they attack just one person, effectively making this person a cyber martyr? It makes no sense. This is the last thing they would want to do. The first rule of war, cyber or traditional is not to empower your enemy. Which in a sense is exactly what happened. They made @cyxymu a kind of cyberwar superstar. If this attack was truly just on one person, I'm sure a more traditional means of elimination of said target would have been a heck of a lot easier to accomplish and would have made a lot less noise. This is especially true in Eastern Europe where people routinely go missing for a lot less. A traditional assassination would have gone completely unnoticed by the West. Instead we are to believe that a very public cyber attack on Twitter, Facebook and Google was orchestrated by the Russians. I'm not sold.
The tactics of the attack don't exactly scream covert Russian operation. They scream botnet for hire. Eastern European zombie networks have become a source of income for entire groups of cybercriminals. A basic botnet running out of eastern Europe for DDoS attacks, can run from $50 to a few thousands dollars depending on the size of the botnet and length of the attack. The most advanced using a fast flux botnet approach (the type most likely used). Anyone with a few bucks can hire their very own botnet and blame anyone they wish. Pointing the botnet at just one person (yourself) is a genius move if you blame someone else. Think of it as a cyberwar Bait & Switch.
If I were a betting man, I'd say that this attack was done using Multi-Stage BGP & DNS Attack Vector. My only real proof is a little common sense as well as the simple reason that a typical HTTP denial of service attack causes a spike in traffic not a drop as illustrated below.
Thursday, August 6, 2009
Facebook & Twitter Down? Did The Cloud Actually Burst?
I feel lost without my social web. As I sit waiting for twitter to return. I figured hey, it's been a while since I've logged into facebook. To my shock and possibly horror, facebook is also down. I can help but wonder if the sudden influx of users from twitter or vice versa facebook outages has caused a domino effect among the largest social networking sites.
Currently I have no idea if the problems are related, but it certainly does show that the two sites are inextricably connected. Notably, both linkedin and friendfeed are responding just find.
Yes, it's time to say this again, hey facebook & twitter where's your cloud bursting contingency plan? If you actually want to be the realtime pulse of the planet, you need to do better, much better.
-- Update --
- LiveJournal is also down
- Looks like facebook is back, not sure if it was limited to Canada or not.
- Wall Street Journal is reporting that the outage is the result of a denial of service attack.
![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-id=e35a09d5-83a0-461a-913f-22cce5768117)
Currently I have no idea if the problems are related, but it certainly does show that the two sites are inextricably connected. Notably, both linkedin and friendfeed are responding just find.
Yes, it's time to say this again, hey facebook & twitter where's your cloud bursting contingency plan? If you actually want to be the realtime pulse of the planet, you need to do better, much better.
-- Update --
- LiveJournal is also down
- Looks like facebook is back, not sure if it was limited to Canada or not.
- Wall Street Journal is reporting that the outage is the result of a denial of service attack.
Wednesday, August 5, 2009
U.S. DoD Holding Cloud Computing "Show & Tell" Workshop
For anyone not currently working with US Department of Defense, but are interested in offering the DoD cloud computing & related network technology. The Defense Venture Catalyst Initiative (DeVenCI) will conduct a workshop this October in the Baltimore MD / Washington DC area to help discover emerging technologies relevant to the Department of Defense (DoD) Global Information Grid (GIG). The workshop will provide selected innovative companies who do not normally conduct business with the Department of Defense with an opportunity to make short presentations to DoD representatives about their technologies and products.
DeVenCI is a U.S. Department of Defense (DoD) activity whose dual goals are to speed DoD adoption of promising new commercial technologies and to encourage broader commercial support of the DoD supply chain. DeVenCI uses workshops, technical expositions, industry outreach, and a publically available web portal (http://devenci.dtic.mil/) to increase the visibility of DoD needs to commercial companies and technology area experts. It provides timely information to DoD users about emerging technical innovations and pilot opportunities. DeVenCI is a catalyst initiative that does not fund the development of new technologies or businesses. Instead, it focuses on knowledge brokering by encouraging and facilitating the sharing of information to speed adoption of emerging technology solutions to DoD user needs.
Companies interested in applying for participation in this workshop should contact DeVenCI via e-mail at [email protected] for an application. All applications must be received on or before August 7, 2009. Selected companies will be responsible for their travel and all other expenses associated with participation in this workshop which will be held in the October timeframe.
DeVenCI is looking for companies who have potential solutions in the following areas:
Information Assurance
a. Toolkits to scan web applications for vulnerabilities
b. Insider threat detection
c. Safe and dynamic data sharing
d. Authentication of users and devices
e. Malware response toolkits
f. Virtual computing technologies for information assurance
Network Applications and Management
a. Real time network monitoring and response
b. Automation of application development and management
c. Virtual computing technologies for network management
d. Next generation social networking
Large Data Networks
a. Large data search and analysis
b. Real time identification and tagging of data
c. Globally scalable distributed storage and data repositories
d. Data agnostic Service Oriented Architectures
e. High speed optical transmission technologies
f. Cloud computing technologies
Mobile Services
a. Location based services, both for wireless and wired
b. Dual use (commercial and military) mobile digital devices
c. Virtual computing technologies for mobile services
--------------------------------------------
Contracting Office Address:
1777 North Kent Street
Suite 9030
Arlington, Virginia 22209
Place of Performance:
Defense Venture Catalyst Initiative
1777 North Kent Street, Suite 9030
Rosslyn, Virginia 22209
United States
Primary Point of Contact.:
DeVenCI Office
[email protected]
![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-id=3683d2f4-6431-41bf-8afd-d99821368ef2)
DeVenCI is a U.S. Department of Defense (DoD) activity whose dual goals are to speed DoD adoption of promising new commercial technologies and to encourage broader commercial support of the DoD supply chain. DeVenCI uses workshops, technical expositions, industry outreach, and a publically available web portal (http://devenci.dtic.mil/) to increase the visibility of DoD needs to commercial companies and technology area experts. It provides timely information to DoD users about emerging technical innovations and pilot opportunities. DeVenCI is a catalyst initiative that does not fund the development of new technologies or businesses. Instead, it focuses on knowledge brokering by encouraging and facilitating the sharing of information to speed adoption of emerging technology solutions to DoD user needs.
Companies interested in applying for participation in this workshop should contact DeVenCI via e-mail at [email protected] for an application. All applications must be received on or before August 7, 2009. Selected companies will be responsible for their travel and all other expenses associated with participation in this workshop which will be held in the October timeframe.
DeVenCI is looking for companies who have potential solutions in the following areas:
Information Assurance
a. Toolkits to scan web applications for vulnerabilities
b. Insider threat detection
c. Safe and dynamic data sharing
d. Authentication of users and devices
e. Malware response toolkits
f. Virtual computing technologies for information assurance
Network Applications and Management
a. Real time network monitoring and response
b. Automation of application development and management
c. Virtual computing technologies for network management
d. Next generation social networking
Large Data Networks
a. Large data search and analysis
b. Real time identification and tagging of data
c. Globally scalable distributed storage and data repositories
d. Data agnostic Service Oriented Architectures
e. High speed optical transmission technologies
f. Cloud computing technologies
Mobile Services
a. Location based services, both for wireless and wired
b. Dual use (commercial and military) mobile digital devices
c. Virtual computing technologies for mobile services
--------------------------------------------
Contracting Office Address:
1777 North Kent Street
Suite 9030
Arlington, Virginia 22209
Place of Performance:
Defense Venture Catalyst Initiative
1777 North Kent Street, Suite 9030
Rosslyn, Virginia 22209
United States
Primary Point of Contact.:
DeVenCI Office
[email protected]
Cloud Singularity is Nigh
Recently I have been thinking a lot of about the concept of singularity in relation to cloud computing. Some in the industry have been pondering that the so called technological singularity is close and quite possibly being accelerated by the rise of internet centric computing (i.e. cloud computing). Apart from being the makings for a great movie plot, I really do love the concept of creating an autonomous and possibly self aware computing system. So I thought I'd go way out into left field and add my two cents to the discussion.
The concept of singularity was first discussed in 1965 when I. J. Good wrote what he described as a coming "intelligence explosion", now referred to as super intelligence. He theorized that if machines could even slightly surpass human intellect, they could improve themselves in ways unforeseen by their designers, and thus recursively augment themselves into far better versions.
Although the concept of a computer program or a device that is smarter, more creative and wiser than any current or past existing human is great in theory. I'm not sure how useful it is as a litmus test for today's networked computing environments. I don't want a smarter computer so much as a more adaptive & efficient infrastructure capable of adjusting to demands with little or no human intervention.I think a much better singularity test is to define whether or not a distributed software application or infrastructure is capable of meeting the basic requirements of a "living system".
The Living System's Theory created by James Grier Miller, defines 20 "critical subsystems", which are defined by their functions and visible in numerous systems, from simple cells to organisms, countries, and societies. According to Miller, living systems are open self-organizing systems that have the special characteristics of life and interact with their environment. Applied to software they exhibit the capability for autonomous behavior as well the ability to evolve (improve or change) and reproduce (self versioning).
Rather then creating one monolithic software framework, I'd envision a distributed "system of systems" made up of many smaller adaptive and continually evolving building blocks. For me it's not about creating a computer as smart or smarter then a human. I'd prefer to see a single software component with the characteristics of single bacteria or even a single cell which can comprise a much broader evolving application.
The concept of singularity was first discussed in 1965 when I. J. Good wrote what he described as a coming "intelligence explosion", now referred to as super intelligence. He theorized that if machines could even slightly surpass human intellect, they could improve themselves in ways unforeseen by their designers, and thus recursively augment themselves into far better versions.
Although the concept of a computer program or a device that is smarter, more creative and wiser than any current or past existing human is great in theory. I'm not sure how useful it is as a litmus test for today's networked computing environments. I don't want a smarter computer so much as a more adaptive & efficient infrastructure capable of adjusting to demands with little or no human intervention.I think a much better singularity test is to define whether or not a distributed software application or infrastructure is capable of meeting the basic requirements of a "living system".
The Living System's Theory created by James Grier Miller, defines 20 "critical subsystems", which are defined by their functions and visible in numerous systems, from simple cells to organisms, countries, and societies. According to Miller, living systems are open self-organizing systems that have the special characteristics of life and interact with their environment. Applied to software they exhibit the capability for autonomous behavior as well the ability to evolve (improve or change) and reproduce (self versioning).
Rather then creating one monolithic software framework, I'd envision a distributed "system of systems" made up of many smaller adaptive and continually evolving building blocks. For me it's not about creating a computer as smart or smarter then a human. I'd prefer to see a single software component with the characteristics of single bacteria or even a single cell which can comprise a much broader evolving application.
Tuesday, August 4, 2009
The Battle for Cloud Application Neutrality
It's hard to believe that it's been a year since we first created the Cloud Computing Interoperability Forum (CCIF) with the goal of defining and enabling interoperable enterprise-class cloud computing platforms through application integration and stakeholder cooperation. Over the last 12 months a lot has happened. For me the most notable change has been how the conversation has shifted from "why use the cloud" & "what is cloud computing" to how to implement it. The need for interoperability among vendors has also become a central point of discussion with the concept being included in recent US federal government cloud requirements. But like it or not the battle for an open cloud ecosystem is far from over.
In the FCC's first major inquiry since newly appointed Federal Communications Commission chairman Julius Genachowski took over the agency on June 29. The FCC has launched an inquiry into AT&T Inc. and Apple Inc. over the rejection of Google's voice application for the Apple iPhone and App store. The move also brings to the forefront the need for what's I've been calling, Cloud Application Neutrality.
The concept of Cloud Application Neutrality extends upon the core tenets of the existing network neutrality debate. A movement which seeks to limit the ability of internet service providers to use their last mile infrastructure to block Internet applications and content (websites, services, protocols); particularly those of competitors. This debate has recently become even important with the rise of cloud computing and popularity of cloud application repositories as well as app store's such as Apple's.
For a lot of emerging cloud service providers a major selling point is the capability of offering unique cloud centric applications - a point of market differentiation. The value typically measured by the amount of third party applications available for a given cloud either directly or thought API access. In the IaaS space the best and broadest example is Amazon's EC2 public AMI directory. A directory of both free and paid applications stacks.
The rise of Cloud App Store's bring some interesting new potential risks, that of vendor lock-out. The prime example is what happens when a cloud provider sees a competitive application is being offered through their own application marketplace. These potential conflicts could result in the arbitrary removal or flat out rejection of competing applications such as Apples public demonstrations have proven. To overcome this risk and create an open yet fair playing field, we must as an emerging industry agree that being "open" is not only limited to API's and interoperability but also the how we conduct and manage cloud marketplaces.
In a BusinessWeek article Spencer Ante notes that "The future of the wireless Web may be at stake. As in there are two different Internets: the open landline Internet and the controlled wireless Internet." Similarly I believe the problem isn't just limited to wireless providers, a similar dichotomy exists within the emerging cloud service provider ecosystem. Cloud computing is at a crossroads and faces the very real potential of becoming a series of "wall gardens" where information and capacity exists behind a series of proprietary API's and application storefronts. We need to take steps now to make sure this doesn't happen.
In the FCC's first major inquiry since newly appointed Federal Communications Commission chairman Julius Genachowski took over the agency on June 29. The FCC has launched an inquiry into AT&T Inc. and Apple Inc. over the rejection of Google's voice application for the Apple iPhone and App store. The move also brings to the forefront the need for what's I've been calling, Cloud Application Neutrality.
The concept of Cloud Application Neutrality extends upon the core tenets of the existing network neutrality debate. A movement which seeks to limit the ability of internet service providers to use their last mile infrastructure to block Internet applications and content (websites, services, protocols); particularly those of competitors. This debate has recently become even important with the rise of cloud computing and popularity of cloud application repositories as well as app store's such as Apple's.
For a lot of emerging cloud service providers a major selling point is the capability of offering unique cloud centric applications - a point of market differentiation. The value typically measured by the amount of third party applications available for a given cloud either directly or thought API access. In the IaaS space the best and broadest example is Amazon's EC2 public AMI directory. A directory of both free and paid applications stacks.
The rise of Cloud App Store's bring some interesting new potential risks, that of vendor lock-out. The prime example is what happens when a cloud provider sees a competitive application is being offered through their own application marketplace. These potential conflicts could result in the arbitrary removal or flat out rejection of competing applications such as Apples public demonstrations have proven. To overcome this risk and create an open yet fair playing field, we must as an emerging industry agree that being "open" is not only limited to API's and interoperability but also the how we conduct and manage cloud marketplaces.
In a BusinessWeek article Spencer Ante notes that "The future of the wireless Web may be at stake. As in there are two different Internets: the open landline Internet and the controlled wireless Internet." Similarly I believe the problem isn't just limited to wireless providers, a similar dichotomy exists within the emerging cloud service provider ecosystem. Cloud computing is at a crossroads and faces the very real potential of becoming a series of "wall gardens" where information and capacity exists behind a series of proprietary API's and application storefronts. We need to take steps now to make sure this doesn't happen.
A Trusted Cloud Entropy Authority
This is an incomplete thought, but I thought I'd take a moment to describe it a bit. In a recent article on Forbes a group of security researchers have brought to light one of the stranger problems that could potentially undermine cloud computing's cyber / cloud security, apparently it's not chaotic enough.
Gordon's comments did get me thinking, maybe there an opportunity to create a trusted cloud authority to provide signed verified and certified entropy. Think of it like a certificate authority (CA) but for chaos. Actually, Amazon Web Service itself could act as this entropy authority via a simple encrypted web service call. I even have a name for it, Simple Entropy Service (SES).
-- Update --
@Samj on twitter pointed me to a website called http://random.org a true random number service that generates randomness via atmospheric noise. Looks cool, maybe this may help solve the problem.
The forbes article describes "a presentation Thursday at the Black Hat cybersecurity conference in Las Vegas, iSec Partners researcher Alex Stamos pointed to what he described as a fundamental problem with cloud computing setups that use virtualization software to partition servers into "images," which are then rented out to customers. Although packing those virtual machines into cloud providers' data centers provides a more flexible and efficient setup than traditional servers, Stamos, along with fellow presenters Andrew Becherer and Nathan Wilcox, argued that virtual machines suffer from a rarely discussed flaw: They don't always have enough access to the random numbers needed to properly encrypt data"This is a very interesting problem. Although not specifically a cloud related it certainly could have implications for virtualization based infrastructure. One of the more insightful ideas to combat the lack of "entropy" comes from a comment on slashdot by Brian Gordon.
Stamos goes on to state "operating system software typically monitors users' mouse movements and key strokes to glean random bits of data that are collected in a so-called "entropy pool," a set of unpredictable numbers that encryption software automatically pulls from to generate random encryption passkeys. In servers, which don't have access to a keyboard or mouse, random numbers are also pulled from the unpredictable movements of the computer's hard drive. If a malicious hacker were to set up his or her own Linux virtual machine in Amazon's EC2 cloud service, for example, he or she could use that machine's entropy pool to better guess at the entropy pools of other recently created Linux-based virtual servers in Amazon's cloud"
Gordon says "How about getting signed entropy from a trusted server on the network/internet?"
Gordon's comments did get me thinking, maybe there an opportunity to create a trusted cloud authority to provide signed verified and certified entropy. Think of it like a certificate authority (CA) but for chaos. Actually, Amazon Web Service itself could act as this entropy authority via a simple encrypted web service call. I even have a name for it, Simple Entropy Service (SES).
-- Update --
@Samj on twitter pointed me to a website called http://random.org a true random number service that generates randomness via atmospheric noise. Looks cool, maybe this may help solve the problem.
Sunday, August 2, 2009
US Federal Cloud Computing Initiative Presentation by GSA
Bob Marcus has shared a recent presentation on the Federal Cloud Computing Initiative by Katie Lewin of GSA presented on June 18. The presentation describes some plans beyond the GSA's current Cloud Computing Storefront Request for Quote (RFQ) which was released a few days ago.
The no nonsense approach to the cloud terminology is also refreshing. GSA breaks it down into three parts
US Federal Cloud Computing Initiative Overview Presentation, (GSA)![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-id=cab83cdc-2a2c-41a9-89c8-16e4bcc82459)
The no nonsense approach to the cloud terminology is also refreshing. GSA breaks it down into three parts
I found slide 11 (Phased Approach for Delivering Cloud Computing) particularly interesting. It outlines a rather ambitious 9 month strategy to rollout a Government focused SaaS, PaaS and IaaS platform by March 2010.
- Private Cloud - Operated solely for an organization
- Community Cloud - Shared by several organizations and supports a specific community that has shared concerns
- Public Cloud - Made available to the general public or a large industry group and is owned by an organization selling cloud services
- Hybrid Cloud - Composition of two or more clouds (private, community, or public) that remain unique entities but are bound together by standardized or proprietary technology that enables data and application portability
US Federal Cloud Computing Initiative Overview Presentation, (GSA)
Subscribe to:
Posts (Atom)
